

-
Ροή Δημοσιεύσεων
- ΑΝΑΚΆΛΥΨΕ
-
Σελίδες
-
Blogs
-
Forum

test jetbrains
-
1 χρήστες τους αρέσει
-
18 Δημοσιεύσεις
-
τις φωτογραφίες μου
-
Videos
-
άλλο
Πρόσφατες ενημερώσεις
-
 BLOG.JETBRAINS.COMHow PhpStorm Helps Maintain PHP Open-Source Projects: Interviews and Real-World ExamplesThe PHP ecosystem is driven by passionate developers building tools that power everything from content management systems right the way through to testing libraries and database layers. Behind each project is a dedicated team working to modernize code, improve performance, and move the ecosystem forward.The fact that many of these teams choose PhpStorm to support their work is a source of pride for all of us at JetBrains and serves as proof of the positive impact on the wider PHP community of our free and discounted license program for open-source contributors. This post highlights standout PHP projects and the people behind them. Whether theyre debugging complex systems or maintaining test suites, PhpStorm helps streamline workflows, reduce friction, and free up time for what matters most building.PHPUnitSebastian Bergmann started PHPUnit as a university project, prompted by a discussion with a professor who thought that a tool like JUnit could not be implemented for PHP. Since then, PHPUnit has been the backbone of PHP testing for over two decades and has shaped how PHP developers write and maintain tests. It remains the go-to testing framework for PHP projects of all sizes.I tried every PHP IDE until I got my hands on PhpStorm the first one that made me more productive, not less. It felt like home right away. I cant imagine working without its code navigation and refactoring tools. Sebastian Bergmann, PHPUnit creatorThe latest release, PHPUnit 12, prioritizes code clarity. A major improvement is the clear distinction between test stubs and mock objects via dedicated APIs. This architectural shift simplifies test code maintenance and readability.Looking ahead, PHPUnit will introduce support for the Open Test Reporting format a modern, extensible alternative to JUnit XML. Initial support is planned for PHPUnit 12.2 (June 2025), with JUnit XML being deprecated in PHPUnit 13 and removed in PHPUnit 14.Doctrine DBALDoctrine DBAL is a widely used database abstraction layer that gives PHP developers a portable, object-oriented API to interact with SQL databases. It powers a wide range of applications and frameworks across the PHP ecosystem.I use PhpStorm daily to run PHPUnit tests locally with various configurations, interact with different databases, manage Docker containers, and run static analysis. Sergei Morozov, Doctrine DBAL maintainerWhile the project is mature and provides most of the essential functionality, ongoing work includes a fundamental rework of schema management, addressing limitations of the original architecture, and ensuring better support for evolving SQL standards and database platforms.CodeIgniterCodeIgniter was created as a lightweight, high-performance PHP framework that prioritizes simplicity and developer freedom. It empowers developers to build on their own terms without rigid conventions a core philosophy that continues to define its appeal.CodeIgniter v4 maintains the core principles of its predecessor while embracing modern software development practices, such as robust testing and integration with tools like PHPStan, Psalm, and Rector.One of CodeIgniter v4s key strengths is its alignment with PHP best practices, allowing PhpStorm to work seamlessly out of the box no extra plugins needed. The IDE instantly understands CodeIgniters patterns and conventions, offering intelligent code completion that streamlines development. This built-in compatibility creates an exceptionally productive experience for our contributors. Matt Gatner, CodeIgniter contributorThe team continues to evolve CI4, focusing on performance, modularity, and a smooth developer experience. Upcoming releases aim to stabilize task and queue packages, expand the modular package library, and improve compatibility with the latest PHP versions all while maintaining the projects original vision.Joomla!Joomla! is a powerful open-source content management system sustained by a global community of volunteers. Its mission is to provide a multilingual, flexible, and secure platform that empowers individuals, small businesses, and nonprofits to publish and collaborate online all without the steep learning curve of alternative systems.PhpStorms static code analyzer helped me clean up docblocks and better manage the framework. It understands Joomla deeply, making development smoother. Hannes Papenberg, Joomla MaintainerPhpStorm shows me how files are connected, catches syntax errors early, and allows me to focus on actual client needs. It gives me a massive advantage over other web developers who dont see the value of using it in their daily processes. Adam Melcher, Joomla ContributorAs a Joomla core developer, PhpStorm has helped me in so many ways. The step debugger, which I use pretty much every single day, helps track down bugs, understand code flows, and generally, seeing what is going on under the hood is precious. The Joomla plugin adds an extra layer of usability as it understands the Joomla codebase and makes navigating the code a lot easier. Roland Dalmulder, Joomla ContributorLooking ahead, Joomla 6 is scheduled for release on October 14, 2025. It will bring further codebase modernization, better SEO tools, and a built-in health checker continuing Joomlas mission to make publishing on the web more inclusive and flexible.These projects represent just a small part of the global open-source effort, but they reflect the values we admire most: curiosity, craftsmanship, and care for the developer community.While each project has its own focus, they all rely on consistent, powerful workflows to maintain high standards and move forward with clarity and JetBrains is proud to support them in this endeavor. If youre an open-source developer, you might be eligible for a free or discounted PhpStorm license read more about the available options to see if you qualify.Whats more, were also delighted to be able to host a celebration of the passion and progress of the PHP community in the form of PHPverse 2025 a free online event taking place on June 17, 2025, where PHPs most influential voices will share their insights on the languages evolution and its future. Join us for inspiring talks, discussions, Q&As, and a special PHP anniversary merch giveaway. Sign Up for Free0 Σχόλια 0 Μοιράστηκε 3 ViewsΠαρακαλούμε συνδέσου στην Κοινότητά μας για να δηλώσεις τι σου αρέσει, να σχολιάσεις και να μοιραστείς με τους φίλους σου!
BLOG.JETBRAINS.COMHow PhpStorm Helps Maintain PHP Open-Source Projects: Interviews and Real-World ExamplesThe PHP ecosystem is driven by passionate developers building tools that power everything from content management systems right the way through to testing libraries and database layers. Behind each project is a dedicated team working to modernize code, improve performance, and move the ecosystem forward.The fact that many of these teams choose PhpStorm to support their work is a source of pride for all of us at JetBrains and serves as proof of the positive impact on the wider PHP community of our free and discounted license program for open-source contributors. This post highlights standout PHP projects and the people behind them. Whether theyre debugging complex systems or maintaining test suites, PhpStorm helps streamline workflows, reduce friction, and free up time for what matters most building.PHPUnitSebastian Bergmann started PHPUnit as a university project, prompted by a discussion with a professor who thought that a tool like JUnit could not be implemented for PHP. Since then, PHPUnit has been the backbone of PHP testing for over two decades and has shaped how PHP developers write and maintain tests. It remains the go-to testing framework for PHP projects of all sizes.I tried every PHP IDE until I got my hands on PhpStorm the first one that made me more productive, not less. It felt like home right away. I cant imagine working without its code navigation and refactoring tools. Sebastian Bergmann, PHPUnit creatorThe latest release, PHPUnit 12, prioritizes code clarity. A major improvement is the clear distinction between test stubs and mock objects via dedicated APIs. This architectural shift simplifies test code maintenance and readability.Looking ahead, PHPUnit will introduce support for the Open Test Reporting format a modern, extensible alternative to JUnit XML. Initial support is planned for PHPUnit 12.2 (June 2025), with JUnit XML being deprecated in PHPUnit 13 and removed in PHPUnit 14.Doctrine DBALDoctrine DBAL is a widely used database abstraction layer that gives PHP developers a portable, object-oriented API to interact with SQL databases. It powers a wide range of applications and frameworks across the PHP ecosystem.I use PhpStorm daily to run PHPUnit tests locally with various configurations, interact with different databases, manage Docker containers, and run static analysis. Sergei Morozov, Doctrine DBAL maintainerWhile the project is mature and provides most of the essential functionality, ongoing work includes a fundamental rework of schema management, addressing limitations of the original architecture, and ensuring better support for evolving SQL standards and database platforms.CodeIgniterCodeIgniter was created as a lightweight, high-performance PHP framework that prioritizes simplicity and developer freedom. It empowers developers to build on their own terms without rigid conventions a core philosophy that continues to define its appeal.CodeIgniter v4 maintains the core principles of its predecessor while embracing modern software development practices, such as robust testing and integration with tools like PHPStan, Psalm, and Rector.One of CodeIgniter v4s key strengths is its alignment with PHP best practices, allowing PhpStorm to work seamlessly out of the box no extra plugins needed. The IDE instantly understands CodeIgniters patterns and conventions, offering intelligent code completion that streamlines development. This built-in compatibility creates an exceptionally productive experience for our contributors. Matt Gatner, CodeIgniter contributorThe team continues to evolve CI4, focusing on performance, modularity, and a smooth developer experience. Upcoming releases aim to stabilize task and queue packages, expand the modular package library, and improve compatibility with the latest PHP versions all while maintaining the projects original vision.Joomla!Joomla! is a powerful open-source content management system sustained by a global community of volunteers. Its mission is to provide a multilingual, flexible, and secure platform that empowers individuals, small businesses, and nonprofits to publish and collaborate online all without the steep learning curve of alternative systems.PhpStorms static code analyzer helped me clean up docblocks and better manage the framework. It understands Joomla deeply, making development smoother. Hannes Papenberg, Joomla MaintainerPhpStorm shows me how files are connected, catches syntax errors early, and allows me to focus on actual client needs. It gives me a massive advantage over other web developers who dont see the value of using it in their daily processes. Adam Melcher, Joomla ContributorAs a Joomla core developer, PhpStorm has helped me in so many ways. The step debugger, which I use pretty much every single day, helps track down bugs, understand code flows, and generally, seeing what is going on under the hood is precious. The Joomla plugin adds an extra layer of usability as it understands the Joomla codebase and makes navigating the code a lot easier. Roland Dalmulder, Joomla ContributorLooking ahead, Joomla 6 is scheduled for release on October 14, 2025. It will bring further codebase modernization, better SEO tools, and a built-in health checker continuing Joomlas mission to make publishing on the web more inclusive and flexible.These projects represent just a small part of the global open-source effort, but they reflect the values we admire most: curiosity, craftsmanship, and care for the developer community.While each project has its own focus, they all rely on consistent, powerful workflows to maintain high standards and move forward with clarity and JetBrains is proud to support them in this endeavor. If youre an open-source developer, you might be eligible for a free or discounted PhpStorm license read more about the available options to see if you qualify.Whats more, were also delighted to be able to host a celebration of the passion and progress of the PHP community in the form of PHPverse 2025 a free online event taking place on June 17, 2025, where PHPs most influential voices will share their insights on the languages evolution and its future. Join us for inspiring talks, discussions, Q&As, and a special PHP anniversary merch giveaway. Sign Up for Free0 Σχόλια 0 Μοιράστηκε 3 ViewsΠαρακαλούμε συνδέσου στην Κοινότητά μας για να δηλώσεις τι σου αρέσει, να σχολιάσεις και να μοιραστείς με τους φίλους σου! -
 BLOG.JETBRAINS.COMFaster Python: Concurrency in async/await and threadingIf you have been coding with Python for a while, especially if you have been using frameworks and libraries such as Fast API and discord.py, then you have probably been using async/await or asyncio. You may have heard statements like multithreading in Python isnt real, and you may also know about the famous (or infamous) GIL in Python. In light of the denial about multithreading in Python, you might be wondering what the difference between async/await and multithreading actually is especially in Python programming. If so, this is the blog post for you!What is multithreading?In programming, multithreading refers to the ability of a program to execute multiple sequential tasks (called threads) concurrently. These threads can run on a single processor core or across multiple cores. However, due to the limitation of the Global Interpreter Lock (GIL), multithreading in Python is only processed on a single core. The exception is nogil (also called thread-free) Python, which removes the GIL and will be covered in part 2 of this series. For this blog post, we will assume that the GIL is always present.What is concurrency?Concurrency in programming means that the computer is doing more than one thing at a time, or seems to be doing more than one thing at a time, even if the different tasks are executed on a single processor. By managing resources and interactions between different parts of a program, different tasks are allowed to make progress independently and in overlapping time intervals.Both asyncio and threading appear concurrent in PythonLoosely speaking, both the asyncio and threading Python libraries enable the appearance of concurrency. However, your CPUs are not doing multiple things at the exact same time. It just seems like they are.Imagine you are hosting a multi-course dinner for some guests. Some of the dishes take time to cook, for example, the pie that needs to be baked in the oven or the soup simmering on the stove. While we are waiting for those to cook, we do not just stand around and wait. We will do something else in the meantime. This is similar to concurrency in Python. Sometimes your Python process is waiting for something to get done. For example, some input/output (I/O) processes are being handled by the operating system, and in this time the Python process is just waiting. We can then use async to let another Python process run while it waits.The difference is who is in chargeIf both asyncio and threading appear concurrent, what is the difference between them? Well, the main difference is a matter of who is in charge of which process is running and when. For async/await, the approach is sometimes called cooperative concurrency. A coroutine or future gives up its control to another coroutine or future to let others have a go. On the other hand, in threading, the operating systems manager will be in control of which process is running.Cooperative concurrency is like a meeting with a microphone being passed around for people to speak. Whoever has the microphone can talk, and when they are done or have nothing else to say, they will pass the microphone to the next person. In contrast, multithreading is a meeting where there is a chairperson who will determine who has the floor at any given time.Writing concurrent code in PythonLets have a look at how concurrency works in Python by writing some example code. We will create a fast food restaurant simulation using both asyncio and threading.How async/await works in PythonThe asyncio package was introduced in Python 3.4, while the async and await keywords were introduced in Python 3.5. One of the main things that make async/await possible is the use of coroutines. Coroutines in Python are actually generators repurposed to be able to pause and pass back to the main function.Now, imagine a burger restaurant where only one staff member is working. The orders are prepared according to a first-in-first-out queue, and no async operations can be performed:import timedef make_burger(order_num): print(f"Preparing burger #{order_num}...") time.sleep(5) # time for making the burger print(f"Burger made #{order_num}")def main(): for i in range(3): make_burger(i)if __name__ == "__main__": s = time.perf_counter() main() elapsed = time.perf_counter() - s print(f"Orders completed in {elapsed:0.2f} seconds.")This will take a while to finish:Preparing burger #0...Burger made #0Preparing burger #1...Burger made #1Preparing burger #2...Burger made #2Orders completed in 15.01 seconds.Now, imagine the restaurant brings in more staff, so that it can perform work concurrently:import asyncioimport timeasync def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def main():order_queue = []for i in range(3):order_queue.append(make_burger(i))await asyncio.gather(*(order_queue))if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")We see the difference between the two:Preparing burger #0...Preparing burger #1...Preparing burger #2...Burger made #0Burger made #1Burger made #2Orders completed in 5.00 seconds.Using the functions provided by asyncio, like run and gather, and the keywords async and await, we have created coroutines that can make burgers concurrently.Now, lets take a step further and create a more complicated simulation. Imagine we only have two workers, and we can only make two burgers at a time.import asyncioimport timeorder_queue = asyncio.Queue()def take_order():for i in range(3):order_queue.put_nowait(make_burger(i))async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while order_queue.qsize() > 0:print(f"{self.name} is working...")task = await order_queue.get()await taskprint(f"{self.name} finished a task...")async def main():staff1 = Staff(name="John")staff2 = Staff(name="Jane")take_order()await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")Here we will use a queue to hold the tasks, and the staff will pick them up.John is working...Preparing burger #0...Jane is working...Preparing burger #1...Burger made #0John finished a task...John is working...Preparing burger #2...Burger made #1Jane finished a task...Burger made #2John finished a task...Orders completed in 10.00 seconds.In this example, we use asyncio.Queue to store the tasks, but it will be more useful if we have multiple types of tasks, as shown in the following example.import asyncioimport timetask_queue = asyncio.Queue()order_num = 0async def take_order():global order_numorder_num += 1print(f"Order burger and fries for order #{order_num:04d}:")burger_num = input("Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = input("Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))print(f"Order #{order_num:04d} queued.")await task_queue.put(take_order())async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def make_fries(order_num):print(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making friesprint(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:print(f"{self.name} is working...")task = await task_queue.get()await taskprint(f"{self.name} finish task...")else:await asyncio.sleep(1) #restasync def main():task_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")In this example, there are multiple tasks, including making fries, which takes less time, and taking orders, which involves getting input from the user.Notice that the program stops waiting for the users input, and even the other staff who are not taking the order stop working in the background. This is because the input function is not async and therefore is not awaited. Remember, control in async code is only released when it is awaited. To fix that, we can replace:input("Number of burgers:")Withawait asyncio.to_thread(input, "Number of burgers:")And we do the same for fries see the code below. Note that now the program runs in an infinite loop. If we need to stop it, we can deliberately crash the program with an invalid input.import asyncioimport timetask_queue = asyncio.Queue()order_num = 0async def take_order():global order_numorder_num += 1print(f"Order burger and fries for order #{order_num:04d}:")burger_num = await asyncio.to_thread(input, "Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = await asyncio.to_thread(input, "Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))print(f"Order #{order_num:04d} queued.")await task_queue.put(take_order())async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def make_fries(order_num):print(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making friesprint(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:print(f"{self.name} is working...")task = await task_queue.get()await taskprint(f"{self.name} finish task...")else:await asyncio.sleep(1) #restasync def main():task_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")By using asyncio.to_thread, we have put the input function into a separate thread (see this reference). Do note, however, that this trick only unblocks I/O-bounded tasks if the Python GIL is present.If you run the code above, you may also see that the standard I/O in the terminal is scrambled. The user I/O and the record of what is happening should be separate. We can put the record into a log to inspect later.import asyncioimport loggingimport timelogger = logging.getLogger(__name__)logging.basicConfig(filename='pyburger.log', level=logging.INFO)task_queue = asyncio.Queue()order_num = 0closing = Falseasync def take_order():global order_num, closingtry:order_num += 1logger.info(f"Taking Order #{order_num:04d}...")print(f"Order burger and fries for order #{order_num:04d}:")burger_num = await asyncio.to_thread(input, "Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = await asyncio.to_thread(input, "Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))logger.info(f"Order #{order_num:04d} queued.")print(f"Order #{order_num:04d} queued, please wait.")await task_queue.put(take_order())except ValueError:print("Goodbye!")logger.info("Closing down... stop taking orders and finish all tasks.")closing = Trueasync def make_burger(order_num):logger.info(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerlogger.info(f"Burger made #{order_num}")async def make_fries(order_num):logger.info(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making frieslogger.info(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:logger.info(f"{self.name} is working...")task = await task_queue.get()await tasktask_queue.task_done()logger.info(f"{self.name} finish task.")elif closing:returnelse:await asyncio.sleep(1) #restasync def main():global task_queuetask_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")print("Welcome to Pyburger!")logger.info("Ready for business!")await asyncio.gather(staff1.working(), staff2.working())logger.info("All tasks finished. Closing now.")if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - slogger.info(f"Orders completed in {elapsed:0.2f} seconds.")In this final code block, we have logged the simulation information in pyburger.log and reserved the terminal for messages for customers. We also catch invalid input during the ordering process and switch a closing flag to True if the input is invalid, assuming the user wants to quit. Once the closing flag is set to True, the worker will return, ending the coroutines infinite while loop.How does threading work in Python?In the example above, we put an I/O-bound task into another thread. You may wonder if we can put all tasks into separate threads and let them run concurrently. Lets try using threading instead of asyncio.Consider the code we have as shown below, where we create burgers concurrently with no limitation put in place:import asyncioimport timeasync def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def main():order_queue = []for i in range(3):order_queue.append(make_burger(i))await asyncio.gather(*(order_queue))if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")```Instead of creating async coroutines to make the burgers, we can just send functions down different threads like this:```import threadingimport timedef make_burger(order_num):print(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")def main():order_queue = []for i in range(3):task = threading.Thread(target=make_burger, args=(i,))order_queue.append(task)task.start()for task in order_queue:task.join()if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")In the first for loop in main, tasks are created in different threads and get a kickstart. The second for loop makes sure all the burgers are made before the program moves on (that is, before it returns to main).It is more complicated when we have only two staff members. Each member of the staff is represented with a thread, and they will take tasks from a normal list where they are all stored.import threadingimport timeorder_queue = []def take_order():for i in range(3):order_queue.append(make_burger(i))def make_burger(order_num):def making_burger():print(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")return making_burgerdef working():while len(order_queue) > 0:print(f"{threading.current_thread().name} is working...")task = order_queue.pop(0)task()print(f"{threading.current_thread().name} finish task...")def main():take_order()staff1 = threading.Thread(target=working, name="John")staff1.start()staff2 = threading.Thread(target=working, name="Jane")staff2.start()staff1.join()staff2.join()if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")When you run the code above, an error may occur in one of the threads, saying that it is trying to get a task from an empty list. You may wonder why this is the case, since we have a condition in the while loop that causes it to continue only if the task_queue is not empty. Nevertheless, we still get an error because we have encountered race conditions.Race conditionsRace conditions can occur when multiple threads attempt to access the same resource or data at the same time and cause problems in the system. The timing and order of when the resource is accessed are important to the program logic, and unpredictable timing or the interleaving of multiple threads accessing and modifying shared data can cause errors.To solve the race condition in our program, we will deploy a lock to the task_queue:queue_lock = threading.Lock()For working, we need to make sure we have access rights to the queue when checking its length and getting tasks from it. While we have the rights, other threads cannot access the queue:def working():while True:with queue_lock:if len(order_queue) == 0:returnelse:task = order_queue.pop(0)print(f"{threading.current_thread().name} is working...")task()print(f"{threading.current_thread().name} finish task...")```Based on what we have learned so far, we can complete our final code with threading like this:```import loggingimport threadingimport timelogger = logging.getLogger(__name__)logging.basicConfig(filename="pyburger_threads.log", level=logging.INFO)queue_lock = threading.Lock()task_queue = []order_num = 0closing = Falsedef take_order():global order_num, closingtry:order_num += 1logger.info(f"Taking Order #{order_num:04d}...")print(f"Order burger and fries for order #{order_num:04d}:")burger_num = input("Number of burgers:")for i in range(int(burger_num)):with queue_lock:task_queue.append(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = input("Number of fries:")for i in range(int(fries_num)):with queue_lock:task_queue.append(make_fries(f"{order_num:04d}-fries{i:02d}"))logger.info(f"Order #{order_num:04d} queued.")print(f"Order #{order_num:04d} queued, please wait.")with queue_lock:task_queue.append(take_order)except ValueError:print("Goodbye!")logger.info("Closing down... stop taking orders and finish all tasks.")closing = Truedef make_burger(order_num):def making_burger():logger.info(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerlogger.info(f"Burger made #{order_num}")return making_burgerdef make_fries(order_num):def making_fries():logger.info(f"Preparing fried #{order_num}...")time.sleep(2) # time for making frieslogger.info(f"Fries made #{order_num}")return making_friesdef working():while True:with queue_lock:if len(task_queue) == 0:if closing:returnelse:task = Noneelse:task = task_queue.pop(0)if task:logger.info(f"{threading.current_thread().name} is working...")task()logger.info(f"{threading.current_thread().name} finish task...")else:time.sleep(1) # restdef main():print("Welcome to Pyburger!")logger.info("Ready for business!")task_queue.append(take_order)staff1 = threading.Thread(target=working, name="John")staff1.start()staff2 = threading.Thread(target=working, name="Jane")staff2.start()staff1.join()staff2.join()logger.info("All tasks finished. Closing now.")if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - slogger.info(f"Orders completed in {elapsed:0.2f} seconds.")If you compare the two code snippets using asyncio and threading, they should have similar results. You may wonder which one is better and why you should choose one over the other.Practically, writing asyncio code is easier than multithreading because we dont have to take care of potential race conditions and deadlocks by ourselves. Controls are passed around coroutines by default, so no locks are needed. However, Python threads do have the potential to run in parallel, just not most of the time with the GIL in place. We can revisit this when we talk about nogil (thread-free) Python in the next blog post.Benefiting from concurrencyWhy do we want to use concurrency in programming? Theres one main reason: speed. Like we have illustrated above, tasks can be completed faster if we can cut down the waiting time. There are different types of waiting in computing, and for each one, we tend to use different methods to save time.I/O-bound tasksA task or program is considered input/output (I/O) bound when its execution speed is primarily limited by the speed of I/O operations, such as reading from a file or network, or waiting for user input. I/O operations are generally slower than other CPU operations, and therefore, tasks that involve lots of them can take significantly more time. Typical examples of these tasks include reading data from a database, handling web requests, or working with large files.Using async/await concurrency can help optimize the waiting time during I/O-bound tasks by unblocking the processing sequence and letting other tasks be taken care of while waiting.Async/await concurrency is beneficial in many Python applications, such as web applications that involve a lot of communication with databases and handling web requests. GUIs (graphical user interfaces) can also benefit from async/await concurrency by allowing background tasks to be performed while the user is interacting with the application.CPU-bound tasksA task or program is considered CPU-bound when its execution speed is primarily limited by the speed of the CPU. Typical examples include image or video processing, like resizing or editing, and complex mathematical calculations, such as matrix multiplication or training machine learning models.Contrary to I/O-bound tasks, CPU-bound tasks can rarely be optimised by using async/await concurrency, as the CPU is already busy working on the tasks. If you have more than one CPU in your machine, or if you can offload some of these tasks to one or more GPUs, then CPU-bound tasks can be finished faster by creating more threads and performing multiprocessing. Multiprocessing can optimise how these CPUs and GPUs are used, which is also why many machine learning and AI models these days are trained on multiple GPUs.This, however, is tough to perform with pure Python code, as Python itself is designed to provide abstract layers so users do not have to control the lower-level computation processes. Moreover, Pythons GIL limits the sharing of Python resources across multiple threads on your computer. Recently, Python 3.13 made it possible to remove the GIL, allowing for true multithreading. We will discuss the GIL, and the ability to go without it, in the next blog post.Sometimes, none of the methods we mentioned above are able to speed up CPU-bound tasks sufficiently. When that is the case, the CPU-bound tasks may need to be broken into smaller ones so that they can be performed simultaneously over multiple threads, multiple processors, or even multiple machines. This is parallel processing, and you may have to rewrite your code completely to implement it. In Python, the multiprocessing package offers both local and remote concurrency, which can be used to work around the limitation of the GIL. We will also look at some examples of that in the next blog post.Debugging concurrent code in PyCharmDebugging async or concurrent code can be hard, as the program is not executed in sequence, meaning it is hard to see where and when the code is being executed. Many developers use print to help trace the flow of the code, but this approach is not recommended, as it is very clumsy and using it to investigate a complex program, like a concurrent one, isnt easy. Plus, it is messy to tidy up after.Many IDEs provide debuggers, which are great for inspecting variables and the flow of the program. Debuggers also provide a clear stack trace across multiple threads. Lets see how we can track the task_queue of our example restaurant simulation in PyCharm.First, we will put down some breakpoints in our code. You can do that by clicking the line number of the line where you want the debugger to pause. The line number will turn into a red dot, indicating that a breakpoint is set there. We will put breakpoints at lines 23, 27, and 65, where the task_queue is changed in different threads.Then we can run the program in debug mode by clicking the little bug icon in the top right.After clicking on the icon, the Debug window will open up. The program will run until it hits the first breakpoint highlighted in the code.Here we see the John thread is trying to pick up the task, and line 65 is highlighted. At this point, the highlighted line has not been executed yet. This is useful when we want to inspect the variables before entering the breakpoint.Lets inspect whats in the task_queue. You can do so simply by starting to type in the Debug window, as shown below.Select or type in task_queue, and then press Enter. You will see that the take_order task is in the queue.Now, lets execute the breakpoint by clicking the Step in button, as shown below.After pressing that and inspecting the Special Variables window that pops up, we see that the task variable is now take_order in the John thread.When querying the task_queue again, we see that now the list is empty.Now lets click the Resume Program button and let the program run.When the program hits the user input part, PyCharm will bring us to the Console window so we can provide the input. Lets say we want two burgers. Type 2 and press Enter.Now we hit the second breakpoint. If we click on Threads & Variables to go back to that window, well see that burger_num is two, as we entered.Now lets step into the breakpoint and inspect the task_queue, just like we did before. We see that one make_burger task has been added.We let the program run again, and if we step into the breakpoint when it stops, we see that Jane is picking up the task.You can inspect the rest of the code yourself. When you are done, simply press the red Stop button at the top of the window.With the debugger in PyCharm, you can follow the execution of your program across different threads and inspect different variables very easily.ConclusionNow we have learned the basics of concurrency in Python, and I hope you will be able to master it with practice. In the next blog post, we will have a look at the Python GIL, the role it plays, and what changes when it is absent.PyCharm provides powerful tools for working with concurrent Python code. As demonstrated in this blog post, the debugger allows the step-by-step inspection of both async and threaded code, helping you track the execution flow, monitor shared resources, and detect issues. With intuitive breakpoints, real-time variable views, seamless console integration for user input, and robust logging support, PyCharm makes it easier to write, test, and debug applications with confidence and clarity. Download PyCharm Now0 Σχόλια 0 Μοιράστηκε 3 Views
BLOG.JETBRAINS.COMFaster Python: Concurrency in async/await and threadingIf you have been coding with Python for a while, especially if you have been using frameworks and libraries such as Fast API and discord.py, then you have probably been using async/await or asyncio. You may have heard statements like multithreading in Python isnt real, and you may also know about the famous (or infamous) GIL in Python. In light of the denial about multithreading in Python, you might be wondering what the difference between async/await and multithreading actually is especially in Python programming. If so, this is the blog post for you!What is multithreading?In programming, multithreading refers to the ability of a program to execute multiple sequential tasks (called threads) concurrently. These threads can run on a single processor core or across multiple cores. However, due to the limitation of the Global Interpreter Lock (GIL), multithreading in Python is only processed on a single core. The exception is nogil (also called thread-free) Python, which removes the GIL and will be covered in part 2 of this series. For this blog post, we will assume that the GIL is always present.What is concurrency?Concurrency in programming means that the computer is doing more than one thing at a time, or seems to be doing more than one thing at a time, even if the different tasks are executed on a single processor. By managing resources and interactions between different parts of a program, different tasks are allowed to make progress independently and in overlapping time intervals.Both asyncio and threading appear concurrent in PythonLoosely speaking, both the asyncio and threading Python libraries enable the appearance of concurrency. However, your CPUs are not doing multiple things at the exact same time. It just seems like they are.Imagine you are hosting a multi-course dinner for some guests. Some of the dishes take time to cook, for example, the pie that needs to be baked in the oven or the soup simmering on the stove. While we are waiting for those to cook, we do not just stand around and wait. We will do something else in the meantime. This is similar to concurrency in Python. Sometimes your Python process is waiting for something to get done. For example, some input/output (I/O) processes are being handled by the operating system, and in this time the Python process is just waiting. We can then use async to let another Python process run while it waits.The difference is who is in chargeIf both asyncio and threading appear concurrent, what is the difference between them? Well, the main difference is a matter of who is in charge of which process is running and when. For async/await, the approach is sometimes called cooperative concurrency. A coroutine or future gives up its control to another coroutine or future to let others have a go. On the other hand, in threading, the operating systems manager will be in control of which process is running.Cooperative concurrency is like a meeting with a microphone being passed around for people to speak. Whoever has the microphone can talk, and when they are done or have nothing else to say, they will pass the microphone to the next person. In contrast, multithreading is a meeting where there is a chairperson who will determine who has the floor at any given time.Writing concurrent code in PythonLets have a look at how concurrency works in Python by writing some example code. We will create a fast food restaurant simulation using both asyncio and threading.How async/await works in PythonThe asyncio package was introduced in Python 3.4, while the async and await keywords were introduced in Python 3.5. One of the main things that make async/await possible is the use of coroutines. Coroutines in Python are actually generators repurposed to be able to pause and pass back to the main function.Now, imagine a burger restaurant where only one staff member is working. The orders are prepared according to a first-in-first-out queue, and no async operations can be performed:import timedef make_burger(order_num): print(f"Preparing burger #{order_num}...") time.sleep(5) # time for making the burger print(f"Burger made #{order_num}")def main(): for i in range(3): make_burger(i)if __name__ == "__main__": s = time.perf_counter() main() elapsed = time.perf_counter() - s print(f"Orders completed in {elapsed:0.2f} seconds.")This will take a while to finish:Preparing burger #0...Burger made #0Preparing burger #1...Burger made #1Preparing burger #2...Burger made #2Orders completed in 15.01 seconds.Now, imagine the restaurant brings in more staff, so that it can perform work concurrently:import asyncioimport timeasync def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def main():order_queue = []for i in range(3):order_queue.append(make_burger(i))await asyncio.gather(*(order_queue))if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")We see the difference between the two:Preparing burger #0...Preparing burger #1...Preparing burger #2...Burger made #0Burger made #1Burger made #2Orders completed in 5.00 seconds.Using the functions provided by asyncio, like run and gather, and the keywords async and await, we have created coroutines that can make burgers concurrently.Now, lets take a step further and create a more complicated simulation. Imagine we only have two workers, and we can only make two burgers at a time.import asyncioimport timeorder_queue = asyncio.Queue()def take_order():for i in range(3):order_queue.put_nowait(make_burger(i))async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while order_queue.qsize() > 0:print(f"{self.name} is working...")task = await order_queue.get()await taskprint(f"{self.name} finished a task...")async def main():staff1 = Staff(name="John")staff2 = Staff(name="Jane")take_order()await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")Here we will use a queue to hold the tasks, and the staff will pick them up.John is working...Preparing burger #0...Jane is working...Preparing burger #1...Burger made #0John finished a task...John is working...Preparing burger #2...Burger made #1Jane finished a task...Burger made #2John finished a task...Orders completed in 10.00 seconds.In this example, we use asyncio.Queue to store the tasks, but it will be more useful if we have multiple types of tasks, as shown in the following example.import asyncioimport timetask_queue = asyncio.Queue()order_num = 0async def take_order():global order_numorder_num += 1print(f"Order burger and fries for order #{order_num:04d}:")burger_num = input("Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = input("Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))print(f"Order #{order_num:04d} queued.")await task_queue.put(take_order())async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def make_fries(order_num):print(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making friesprint(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:print(f"{self.name} is working...")task = await task_queue.get()await taskprint(f"{self.name} finish task...")else:await asyncio.sleep(1) #restasync def main():task_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")In this example, there are multiple tasks, including making fries, which takes less time, and taking orders, which involves getting input from the user.Notice that the program stops waiting for the users input, and even the other staff who are not taking the order stop working in the background. This is because the input function is not async and therefore is not awaited. Remember, control in async code is only released when it is awaited. To fix that, we can replace:input("Number of burgers:")Withawait asyncio.to_thread(input, "Number of burgers:")And we do the same for fries see the code below. Note that now the program runs in an infinite loop. If we need to stop it, we can deliberately crash the program with an invalid input.import asyncioimport timetask_queue = asyncio.Queue()order_num = 0async def take_order():global order_numorder_num += 1print(f"Order burger and fries for order #{order_num:04d}:")burger_num = await asyncio.to_thread(input, "Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = await asyncio.to_thread(input, "Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))print(f"Order #{order_num:04d} queued.")await task_queue.put(take_order())async def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def make_fries(order_num):print(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making friesprint(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:print(f"{self.name} is working...")task = await task_queue.get()await taskprint(f"{self.name} finish task...")else:await asyncio.sleep(1) #restasync def main():task_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")await asyncio.gather(staff1.working(), staff2.working())if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")By using asyncio.to_thread, we have put the input function into a separate thread (see this reference). Do note, however, that this trick only unblocks I/O-bounded tasks if the Python GIL is present.If you run the code above, you may also see that the standard I/O in the terminal is scrambled. The user I/O and the record of what is happening should be separate. We can put the record into a log to inspect later.import asyncioimport loggingimport timelogger = logging.getLogger(__name__)logging.basicConfig(filename='pyburger.log', level=logging.INFO)task_queue = asyncio.Queue()order_num = 0closing = Falseasync def take_order():global order_num, closingtry:order_num += 1logger.info(f"Taking Order #{order_num:04d}...")print(f"Order burger and fries for order #{order_num:04d}:")burger_num = await asyncio.to_thread(input, "Number of burgers:")for i in range(int(burger_num)):await task_queue.put(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = await asyncio.to_thread(input, "Number of fries:")for i in range(int(fries_num)):await task_queue.put(make_fries(f"{order_num:04d}-fries{i:02d}"))logger.info(f"Order #{order_num:04d} queued.")print(f"Order #{order_num:04d} queued, please wait.")await task_queue.put(take_order())except ValueError:print("Goodbye!")logger.info("Closing down... stop taking orders and finish all tasks.")closing = Trueasync def make_burger(order_num):logger.info(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerlogger.info(f"Burger made #{order_num}")async def make_fries(order_num):logger.info(f"Preparing fries #{order_num}...")await asyncio.sleep(2) # time for making frieslogger.info(f"Fries made #{order_num}")class Staff:def __init__(self, name):self.name = nameasync def working(self):while True:if task_queue.qsize() > 0:logger.info(f"{self.name} is working...")task = await task_queue.get()await tasktask_queue.task_done()logger.info(f"{self.name} finish task.")elif closing:returnelse:await asyncio.sleep(1) #restasync def main():global task_queuetask_queue.put_nowait(take_order())staff1 = Staff(name="John")staff2 = Staff(name="Jane")print("Welcome to Pyburger!")logger.info("Ready for business!")await asyncio.gather(staff1.working(), staff2.working())logger.info("All tasks finished. Closing now.")if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - slogger.info(f"Orders completed in {elapsed:0.2f} seconds.")In this final code block, we have logged the simulation information in pyburger.log and reserved the terminal for messages for customers. We also catch invalid input during the ordering process and switch a closing flag to True if the input is invalid, assuming the user wants to quit. Once the closing flag is set to True, the worker will return, ending the coroutines infinite while loop.How does threading work in Python?In the example above, we put an I/O-bound task into another thread. You may wonder if we can put all tasks into separate threads and let them run concurrently. Lets try using threading instead of asyncio.Consider the code we have as shown below, where we create burgers concurrently with no limitation put in place:import asyncioimport timeasync def make_burger(order_num):print(f"Preparing burger #{order_num}...")await asyncio.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")async def main():order_queue = []for i in range(3):order_queue.append(make_burger(i))await asyncio.gather(*(order_queue))if __name__ == "__main__":s = time.perf_counter()asyncio.run(main())elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")```Instead of creating async coroutines to make the burgers, we can just send functions down different threads like this:```import threadingimport timedef make_burger(order_num):print(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")def main():order_queue = []for i in range(3):task = threading.Thread(target=make_burger, args=(i,))order_queue.append(task)task.start()for task in order_queue:task.join()if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")In the first for loop in main, tasks are created in different threads and get a kickstart. The second for loop makes sure all the burgers are made before the program moves on (that is, before it returns to main).It is more complicated when we have only two staff members. Each member of the staff is represented with a thread, and they will take tasks from a normal list where they are all stored.import threadingimport timeorder_queue = []def take_order():for i in range(3):order_queue.append(make_burger(i))def make_burger(order_num):def making_burger():print(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerprint(f"Burger made #{order_num}")return making_burgerdef working():while len(order_queue) > 0:print(f"{threading.current_thread().name} is working...")task = order_queue.pop(0)task()print(f"{threading.current_thread().name} finish task...")def main():take_order()staff1 = threading.Thread(target=working, name="John")staff1.start()staff2 = threading.Thread(target=working, name="Jane")staff2.start()staff1.join()staff2.join()if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - sprint(f"Orders completed in {elapsed:0.2f} seconds.")When you run the code above, an error may occur in one of the threads, saying that it is trying to get a task from an empty list. You may wonder why this is the case, since we have a condition in the while loop that causes it to continue only if the task_queue is not empty. Nevertheless, we still get an error because we have encountered race conditions.Race conditionsRace conditions can occur when multiple threads attempt to access the same resource or data at the same time and cause problems in the system. The timing and order of when the resource is accessed are important to the program logic, and unpredictable timing or the interleaving of multiple threads accessing and modifying shared data can cause errors.To solve the race condition in our program, we will deploy a lock to the task_queue:queue_lock = threading.Lock()For working, we need to make sure we have access rights to the queue when checking its length and getting tasks from it. While we have the rights, other threads cannot access the queue:def working():while True:with queue_lock:if len(order_queue) == 0:returnelse:task = order_queue.pop(0)print(f"{threading.current_thread().name} is working...")task()print(f"{threading.current_thread().name} finish task...")```Based on what we have learned so far, we can complete our final code with threading like this:```import loggingimport threadingimport timelogger = logging.getLogger(__name__)logging.basicConfig(filename="pyburger_threads.log", level=logging.INFO)queue_lock = threading.Lock()task_queue = []order_num = 0closing = Falsedef take_order():global order_num, closingtry:order_num += 1logger.info(f"Taking Order #{order_num:04d}...")print(f"Order burger and fries for order #{order_num:04d}:")burger_num = input("Number of burgers:")for i in range(int(burger_num)):with queue_lock:task_queue.append(make_burger(f"{order_num:04d}-burger{i:02d}"))fries_num = input("Number of fries:")for i in range(int(fries_num)):with queue_lock:task_queue.append(make_fries(f"{order_num:04d}-fries{i:02d}"))logger.info(f"Order #{order_num:04d} queued.")print(f"Order #{order_num:04d} queued, please wait.")with queue_lock:task_queue.append(take_order)except ValueError:print("Goodbye!")logger.info("Closing down... stop taking orders and finish all tasks.")closing = Truedef make_burger(order_num):def making_burger():logger.info(f"Preparing burger #{order_num}...")time.sleep(5) # time for making the burgerlogger.info(f"Burger made #{order_num}")return making_burgerdef make_fries(order_num):def making_fries():logger.info(f"Preparing fried #{order_num}...")time.sleep(2) # time for making frieslogger.info(f"Fries made #{order_num}")return making_friesdef working():while True:with queue_lock:if len(task_queue) == 0:if closing:returnelse:task = Noneelse:task = task_queue.pop(0)if task:logger.info(f"{threading.current_thread().name} is working...")task()logger.info(f"{threading.current_thread().name} finish task...")else:time.sleep(1) # restdef main():print("Welcome to Pyburger!")logger.info("Ready for business!")task_queue.append(take_order)staff1 = threading.Thread(target=working, name="John")staff1.start()staff2 = threading.Thread(target=working, name="Jane")staff2.start()staff1.join()staff2.join()logger.info("All tasks finished. Closing now.")if __name__ == "__main__":s = time.perf_counter()main()elapsed = time.perf_counter() - slogger.info(f"Orders completed in {elapsed:0.2f} seconds.")If you compare the two code snippets using asyncio and threading, they should have similar results. You may wonder which one is better and why you should choose one over the other.Practically, writing asyncio code is easier than multithreading because we dont have to take care of potential race conditions and deadlocks by ourselves. Controls are passed around coroutines by default, so no locks are needed. However, Python threads do have the potential to run in parallel, just not most of the time with the GIL in place. We can revisit this when we talk about nogil (thread-free) Python in the next blog post.Benefiting from concurrencyWhy do we want to use concurrency in programming? Theres one main reason: speed. Like we have illustrated above, tasks can be completed faster if we can cut down the waiting time. There are different types of waiting in computing, and for each one, we tend to use different methods to save time.I/O-bound tasksA task or program is considered input/output (I/O) bound when its execution speed is primarily limited by the speed of I/O operations, such as reading from a file or network, or waiting for user input. I/O operations are generally slower than other CPU operations, and therefore, tasks that involve lots of them can take significantly more time. Typical examples of these tasks include reading data from a database, handling web requests, or working with large files.Using async/await concurrency can help optimize the waiting time during I/O-bound tasks by unblocking the processing sequence and letting other tasks be taken care of while waiting.Async/await concurrency is beneficial in many Python applications, such as web applications that involve a lot of communication with databases and handling web requests. GUIs (graphical user interfaces) can also benefit from async/await concurrency by allowing background tasks to be performed while the user is interacting with the application.CPU-bound tasksA task or program is considered CPU-bound when its execution speed is primarily limited by the speed of the CPU. Typical examples include image or video processing, like resizing or editing, and complex mathematical calculations, such as matrix multiplication or training machine learning models.Contrary to I/O-bound tasks, CPU-bound tasks can rarely be optimised by using async/await concurrency, as the CPU is already busy working on the tasks. If you have more than one CPU in your machine, or if you can offload some of these tasks to one or more GPUs, then CPU-bound tasks can be finished faster by creating more threads and performing multiprocessing. Multiprocessing can optimise how these CPUs and GPUs are used, which is also why many machine learning and AI models these days are trained on multiple GPUs.This, however, is tough to perform with pure Python code, as Python itself is designed to provide abstract layers so users do not have to control the lower-level computation processes. Moreover, Pythons GIL limits the sharing of Python resources across multiple threads on your computer. Recently, Python 3.13 made it possible to remove the GIL, allowing for true multithreading. We will discuss the GIL, and the ability to go without it, in the next blog post.Sometimes, none of the methods we mentioned above are able to speed up CPU-bound tasks sufficiently. When that is the case, the CPU-bound tasks may need to be broken into smaller ones so that they can be performed simultaneously over multiple threads, multiple processors, or even multiple machines. This is parallel processing, and you may have to rewrite your code completely to implement it. In Python, the multiprocessing package offers both local and remote concurrency, which can be used to work around the limitation of the GIL. We will also look at some examples of that in the next blog post.Debugging concurrent code in PyCharmDebugging async or concurrent code can be hard, as the program is not executed in sequence, meaning it is hard to see where and when the code is being executed. Many developers use print to help trace the flow of the code, but this approach is not recommended, as it is very clumsy and using it to investigate a complex program, like a concurrent one, isnt easy. Plus, it is messy to tidy up after.Many IDEs provide debuggers, which are great for inspecting variables and the flow of the program. Debuggers also provide a clear stack trace across multiple threads. Lets see how we can track the task_queue of our example restaurant simulation in PyCharm.First, we will put down some breakpoints in our code. You can do that by clicking the line number of the line where you want the debugger to pause. The line number will turn into a red dot, indicating that a breakpoint is set there. We will put breakpoints at lines 23, 27, and 65, where the task_queue is changed in different threads.Then we can run the program in debug mode by clicking the little bug icon in the top right.After clicking on the icon, the Debug window will open up. The program will run until it hits the first breakpoint highlighted in the code.Here we see the John thread is trying to pick up the task, and line 65 is highlighted. At this point, the highlighted line has not been executed yet. This is useful when we want to inspect the variables before entering the breakpoint.Lets inspect whats in the task_queue. You can do so simply by starting to type in the Debug window, as shown below.Select or type in task_queue, and then press Enter. You will see that the take_order task is in the queue.Now, lets execute the breakpoint by clicking the Step in button, as shown below.After pressing that and inspecting the Special Variables window that pops up, we see that the task variable is now take_order in the John thread.When querying the task_queue again, we see that now the list is empty.Now lets click the Resume Program button and let the program run.When the program hits the user input part, PyCharm will bring us to the Console window so we can provide the input. Lets say we want two burgers. Type 2 and press Enter.Now we hit the second breakpoint. If we click on Threads & Variables to go back to that window, well see that burger_num is two, as we entered.Now lets step into the breakpoint and inspect the task_queue, just like we did before. We see that one make_burger task has been added.We let the program run again, and if we step into the breakpoint when it stops, we see that Jane is picking up the task.You can inspect the rest of the code yourself. When you are done, simply press the red Stop button at the top of the window.With the debugger in PyCharm, you can follow the execution of your program across different threads and inspect different variables very easily.ConclusionNow we have learned the basics of concurrency in Python, and I hope you will be able to master it with practice. In the next blog post, we will have a look at the Python GIL, the role it plays, and what changes when it is absent.PyCharm provides powerful tools for working with concurrent Python code. As demonstrated in this blog post, the debugger allows the step-by-step inspection of both async and threaded code, helping you track the execution flow, monitor shared resources, and detect issues. With intuitive breakpoints, real-time variable views, seamless console integration for user input, and robust logging support, PyCharm makes it easier to write, test, and debug applications with confidence and clarity. Download PyCharm Now0 Σχόλια 0 Μοιράστηκε 3 Views -
Kotlin for Server-Side Development: Community Content Roundup #2The Kotlin community keeps delivering valuable content for server-side development. From gRPC best practices to hands-on Ktor tutorials and Spring integrations, here are the latest highlights. [Article] Kotlin Tips and Tricks You May Not Know: #6 Inject Functions in Spring Boot Elena van Engelen-Maslova shares how to inject functions in Spring Boot for cleaner and more flexible Kotlin code. A simple trick with real impact. [Article] Learning Ktor Through a Spring Boot Lens. Part 1 Rafa Maciak compares Spring Boot and Ktor to help developers familiar with Spring get up to speed with Kotlin-first backend development. [Video] Spring for GraphQL with Kotlin Coroutines Piotr Wolak walks you through building reactive GraphQL APIs with Spring for GraphQL and Kotlin coroutines. [Article series] Kotlin + gRPC by Lucas Fugisawa A comprehensive series covering real-world practices for building gRPC services in Kotlin:Build your first service in four stepsEnhance Protobuf schema design with Optional, Repeated, Maps, Enums, Oneof and backwards compatibilityNesting, Composition, Validations, and Idiomatic Builder DSLStreaming, Deadlines, and Structured Error HandlingTooling, CI/CD, and Architectural Practices [Video] Ktor Server Full Crash Course For Beginners | Build a REST Api in Ktor with JWT Auth | Blog CRUD Api Sunil Kumar shares a complete beginner-friendly guide to building a secure REST API with Ktor and JWT authentication.Want to be featured next?If youre building backends with Kotlin and sharing your knowledge whether its a blog post, video, or sample project tag it with #KotlinServerSide.We regularly browse community content and highlight the most useful picks on our blog, @Kotlin X, and Kotlin Slack (get an invite here).Keep sharing, and well keep amplifying.0 Σχόλια 0 Μοιράστηκε 3 Views
-
BLOG.JETBRAINS.COMText Blocks in Java: Perfect for Multiline StringsYouve likely used String variables to store values that span multiple lines, such as LLM prompts, JSON, HTML, XML, code snippets, and other such values.Some of these, such as a JSON value, include double quotes as part of the data. Imagine the inconvenience of using backslashes (\) to escape those quotes, indenting lines using newlines, tabs, or spaces, and adding a concatenation operator at the end of each line. Coding such string values is a nightmare. The resulting string is not just hard to write, but also hard to read. Language-specific errors, like a missing comma in a JSON value, can easily creep in.Dont worry, theres already a solution. Java 15 introduced Text Blocks, multiline strings that make it easier to define data that spans multiple lines. Text Blocks remove the need for concatenation operators or escape sequences when working with HTML, XML, JSON, or SQL queries stored as strings. The values are easier to read, and its simpler to spot issues like missing spaces in SQL queries or a missing comma in a JSON value.Lets understand the benefits of using Text Blocks with an example.An example what are the existing pain pointsImagine you need to store the following JSON text in your Java code:{"name": "Sonam Wangchuk""movement": "#ILiveSimply","result": "Let planet simply live"}This JSON value can be stored as a multi line String value (without using a TextBlock) as follows:String myJson = "{\n" +" \"name\": \"Sonam Wangchuk\"\n" +" \"movement\": \"#ILiveSimply\",\n" +" \"result\": \"Let planet simply live\"\n" +"}";Writing the preceding code manually can be a nightmare. Escape characters and concatenation operators make it hard to write and read. To include double quotes within a string, you must escape them using a backslash (since is also a string delimiter). To preserve the formatting of the JSON object, you need to add whitespace such as new lines, tabs, or spaces.With all that formatting overhead, you probably missed that the JSON above is missing a comma at the end of the first line. This missing comma can cause a parsing error later if you try to convert the string into a JSON object.Lets see how Text Blocks can help.Using Text BlocksTextBlocks are multiline Strings (their type is java.lang.String). By using Text Blocks, you can store the previous String value, as follows:String myJson = """{"name": "Sonam Wangchuk""movement": "#ILiveSimply","result": "Let planet simply live"}""";Text Blocks are simple to create, read, and edit. They eliminate the need for concatenation operators and (most) escape sequences when working with String values that span more than one line, as shown below:The next section covers the syntax details of text blocks. If youre already familiar with them, feel free to skip ahead.Syntax of TextBlocksHere are a couple of syntax rules to follow when you are working with Text Blocks.Opening and closing delimiter """Unlike the single double quotes (") used for regular String values, Text Blocks use three double quotes (""") as their opening and closing delimiters. The opening delimiter can be followed by zero or more whitespaces, but it must be followed by a line terminator. A Text Block value begins after this line terminator.If a Text Block doesnt include a newline character immediately after the opening """, IntelliJ IDEA can detect this and prompt you to correct it:Incidental white spacesWhat rules does the compiler follow to include or exclude leading and trailing whitespace in a Text Block? Before we answer this question, lets first understand what whitespaces are. When we talk about a whitespace in Java Text Blocks, it can refer to different types of characters, such as:A space The standard space character we use to separate wordsTabs The popular Tab characters, that is, ('\t'). Wars have been fought over whether to use tabs or space to indent code :)Line breaks Newline characters ('\n' on Unix/Linux/macOS, or '\r\n' on Windows)Carriage returns ('\r')First, lets talk about how the leading white spaces are handled in a Text Block.Leading spacesWhy do you need leading spaces? You would usually add tabs or spaces to values, such as a JSON, to align them vertically in your code. In Text Blocks, the leftmost non-whitespace character on any of the lines or the leftmost closing delimiter defines where meaningful white space begins. IntelliJ IDEA helps you view this position using a vertical line a feature that I absolutely love about Text Blocks support in IntelliJ IDEA.Heres how the vertical bar in IntelliJ IDEA lets you visualize the starting position of your Text Block values:Just in case you cant view the vertical green line shown in the preceding image, use Shift+Shift, Find Show indent guides, and enable it in IntelliJ IDEA.The following image shows another way to understand which leading spaces are included in your text blocks blue rectangles represent the spaces that are not part of your textblock and the light green rectangles represent the leading spaces that are included in your text block:If you move the closing triple quotes to the left, the white spaces included in the textblock changes, as shown in the following image:Trailing white spacesBy default, the trailing white spaces are removed in Text Block values. IntelliJ IDEA can detect when you add trailing white spaces in your textblocks. It would highlight those spaces (to ensure you didnt add them by mistake).When you click Alt + Enter, it could prompt you to either Escape trailing whitespace characters, or Remove trailing whitespace characters. If you choose the former option, IntelliJ IDEA will add \s at the end (\s represents a single space), as shown in the following gif:Where would you use a trailing white space?Imagine you are using a method from a library that reads the first 40 characters of a line to extract two values from it, and store it in a Map, as follows:public Map<String, String> parseFixedWidthData(String fixedWidthData) {Map<String, String> result = new HashMap<>();String[] lines = fixedWidthData.split("\n");for (String line : lines) {String field1 = line.substring(0, 19).trim();String field2 = line.substring(20, 39).trim();result.put(field1, field2);}return result;}If you are using a textblock to pass value to the method parseFixedWidthData, you should define it as follows, escaping the trailing whitespaces, so the the preceding method doesnt throw an IndexOutOfBounds exception:String fixedWidthData = """CUSTOMER_NAME JOHN DOE \sACCOUNT_NUMBER 12345678-9879 \sAGE 45 \s""";Continuation char \When you place your text on a new line in a text block, a new line char is added to your String value. Imagine using a textblock to store a store long URL so that it is easy to read, as follows:String apiUrl = """ https://www.alamy.com/stock-photo-abstract-geometric-pattern-hipster-fashion-design-print-hexagonal-175905258.html? imageid=0DF26DE9-AC7B-4C78-8770-E1AC9EC8783A &p=379271 &pn=1 &searchId=8cf93ae4926578c6f55e3756c4010a71&searchtype=0""";However, if you use the preceding text block to connect to a URL and retrieve a response, the code will throw an exception. Inclusion of \n in the URL makes it an invalid URL. To address it, you can use the continuation character, that is, \ at the end of a line in your text block (so that the resulting string doesnt include a new line character):String apiUrl = """ https://www.alamy.com/stock-photo-abstract-geometric-pattern-hipster-fashion-design-print-hexagonal-175905258.html?\ imageid=0DF26DE9-AC7B-4C78-8770-E1AC9EC8783A\ &p=379271\ &pn=1\ &searchId=8cf93ae4926578c6f55e3756c4010a71&searchtype=0""";More about TextBlocksWith the syntax rules under your belt, lets learn more about Text blocks.Not a String variationJava isnt adding a variation of type String with Text Blocks. They are compiled to regular String instances (java.lang.String). You can think of Textblocks as syntactic sugar that allows you to write Strings without using the concatenating operators and escape sequences. If you decompile a class that defines a text block, youll see that they are compiled to regular strings with single pair of double quotes as the delimiter, as shown in the following gif (the top bar mentions that you are viewing a Decompiled .class file):Call any String method on a text blockSince there is just one java.lang.String type (not a variation for Text blocks), it means that you can call all String methods on text blocks:Convert a text block to a regular stringImagine you are migrating your codebase to a development environment that doesnt support Textblocks (Java 14 or earlier versions). In such case, you can invoke Context Actions to convert a Text Block to a regular String literal:Language Injections in TextblocksInjecting a language into Text Blocks in IntelliJ IDEA enables syntax highlighting and real-time error detection, helping to catch issues such as unclosed JSON values or HTML tags, missing or mismatched quotes in attributes, inconsistent indentation, and unescaped special characters. You also get IntelliJ IDEAs support like code completion, and value validation.The following gif shows how you can inject JSON as a language in a text block (language injection in IntelliJ IDEA applies to regular strings too):As you can see, the language injection option enables you to choose from multiple options (including JSON).Practical examples where to use Text BlocksApart from using Textblocks to store JSON data (as shown in the preceding sections), you can think of using Text Blocks to store values that usually span multiple lines such as XML, HTML data, or code snippets written in other programming languages. This section highlights the practical examples where you can use text blocks.1. ASCII ArtYou can use textblock to store and output ASCII art, such as the following:String textblock = """ """;2. Logging dataImagine while working with an online shopping application, you need to log a message with order details, if the quantity for a product in an order is 0 or negative. It is common to create a String that includes literals, such as, Invalid order, and order details that can be accessed using variables like orderId, etc. Heres a sample code to accomplish this (focus on the concatenated String):public void processOrder(int orderId, String product, int qty, LocalDate orderDate) {if (qty <= 0) {String errorMessage = "Invalid order quantity:" + qty +"for product" + product + ",order ID" + orderId;logger.error(errorMessage);return;}//.. Remaining code}The code seems harmless. However, Ive often missed adding spaces before and after the literal text values in similar code, generating a log message similar to the following that is hard to read:Invalid order quantity: -5for productWidget,order ID12345A safer bet would be to use textblocks for this logging message that can help you spot the missing spaces. Even if you miss adding spaces, the new line characters can space out the log messages:public void processOrder(int orderId, String product, int qty, LocalDate orderDate) {if (qty <= 0) {String errorMessage = ("""Invalid order quantity:%dfor product %s,order ID %d""").formatted(qty, product, orderId);logger.info(errorMessage);System.out.println(errorMessage);return;}//.. Remaining code}3. XML or HTML dataHeres an example of a Text Block storing a HTML value:String html = """<HTML><BODY><P>Stop generating 6 million tons of plastic waste</P><UL><LI>Keep a spoon, fork, knife in your bag.</LI><LI>Avoid using single use plastic cutlery.</LI></UL></BODY></HTML>""";4. Complex JSON dataIn the beginning of this blog post, I covered how text blocks can help eliminate the clutter. The clutter increases manifolds, when you start working with more complex JSON objects, as follows:String json = "{\n" +" \"cod\": \"200\",\n" +" \"city\": {\n" +" \"id\": 524901,,,,\n" +" \"name\": \"GreatCity\",\n" +" \"country\": \"AwesomeCountry\",\n" +" \"coord\": {\n" +" \"lat\": 55.7522,\n" +" \"lon\": 37.6156\n" +" }\n" +" }\n" +"}";With textblocks, the cognitive load reduces, as you can see in the following code snippet:String json = """{"cod": "200","city": {"id": 524901,,,,"name": "GreatCity","country": "AwesomeCountry","coord": {"lat": 55.7522,"lon": 37.6156}}}""";Perhaps you can inject language in the preceding text block and determine the syntax errors with the JSON value.5. Multiline String valuesHeres just a long line of String, stored using Text Blocks:String aLongString = """I'm a long String value, which can't fit on aSingle line."Hey!", would you prefer a cup of coffee?"Yes, please".""";Text Blocks take off the visual clutter from multiline strings which existed in the form of concatenation operators and escape sequences.6. SQL QueriesImagine using the following code to store a SQL query:String query ="SELECT name, age" +"FROM EMP" +"WHERE name = \'John\'" +"AND age > 20";The preceding code represents an invalid query. Due to missing spaces at the end of each line, this query will be interpreted as the following:SELECT name, ageFROM EMPWHERE name = 'John'AND age > 20You can address these issues by using text blocks:String query = """SELECT name, ageFROM EMPWHERE name = 'John'AND age > 20""";7. Email templates multiline string values with literal and variable valuesWhen concatenating string literals with variable values, it is easy to miss adding a single space in string literal, right before or after a variable value. It could result in poorly formatted output, or output that is not-so-readable. It could also result in displaying output you didnt expect due to those missing spaces. Consider the following code that uses a combination of string literals and variable values to send a text to a customer:String username = "Alice"; String topic = "Java Records"; String previousContext = "We were discussing immutable data classes."; String email = "Hi" + username + ",\n\n" + "Let's continue our discussion about " + topic + ".\n" + "For context, " + previousContext + "\n\n" + "Can you tell me more about what specific aspects of" + topic + "you're interested in?";You could use TextBlock and formatted(), so that the variable substitution is cleaner:String email = """ Hi %s, Let's continue our discussion about %s. For context, %s Can you tell me more about what specific aspects of %s you're interested in? """.formatted(username, topic, previousContext, topic);8. Creating simple billsYou can create simple bills (such as the following) to print using textblocks:-------------------------------------------------------------------------------------- Your Neighbourhood Art Supplies Store--------------------------------------------------------------------------------------Date: 2023-10-20 Invoice Number: 12345 Customer DetailsName: John Smith Address: 123 Main Street City: Smallville Phone: 555-123-4567 --------------------------------------------------------------------------------------S.No. Item Name Quantity Unit Price($) Total($)--------------------------------------------------------------------------------------1 Acrylic Paint Set 1 20.00 20.002 Watercolor Brushes 5 15.00 75.003 Sketchbook 12 10.00 120.004 Oil Paints Set 1 25.00 25.005 Canvas Panels (5-pack) 6 12.00 72.00--------------------------------------------------------------------------------------Subtotal: $82.0Sales Tax (6%): $4.92Total Amount: $86.92;-------------------------------------------------------------------------------------- Thank you for shopping with us!--------------------------------------------------------------------------------------Code Migrations using text blocks instead of a regular stringThe release of Java 25, the next LTS version, is around the corner. If you plan to migrate your existing codebases using JDK version 14 or earlier to a newer version, you can start using Text Blocks in your code.To migrate all eligible multiline String values currently stored across multiple lines using concatenation operators to Text Blocks, you can proceed in two ways. The first approach is to run the inspection Text blocks can be used on your entire project or selected directories. In the Problems view window that opens, you can apply these changes individually or in a batch.To demonstrate this feature, I forked an open-source project from GitHub, JSON-java, and ran the inspection Text blocks can be used, as shown in the following GIF:The second approach is to create a new profile in Settings, say, Migrate to 24, and add all the migration inspections to this profile. Then, you can execute the Inspect Code command and run this inspection profile on your codebase. Use the Problems view window to accept multiple changes at once or review them individually.SummaryText blocks in Java are syntactic sugar to make it easy for you to create string values that span multiple lines, without needing to use concatenation operators or escape sequences. This makes it easier to read and write such values, reducing cognitive load for us developers. Since the values are clutter-free, you can also spot syntax errors in these multiline values, such as a missing quote or comma. By injecting a language or a reference into these text blocks, IntelliJ IDEA can help you further by highlighting these errors and even suggesting how to fix them.Text blocks start and end with three double quotes. By default, trailing whitespaces are ignored in text blocks. To includeor in other words, escapethe trailing whitespaces, use \s. To join two lines, add a backslash (\) at the end of the first line.Text blocks are quite useful when youre working with data that usually spans multiple lines, such as JSON, SQL queries, HTML, XML, and others. You could use text blocks to output beautiful line art, format log messages, or even generate simple bills for your neighbourhood stores.The release of Java 25 is around the corner. If youre still working with an older version of the JDK, such as 8 or 11, I recommend moving to a newer version so you can benefit from newer features like text blocks.Happy coding!0 Σχόλια 0 Μοιράστηκε 3 Views
-
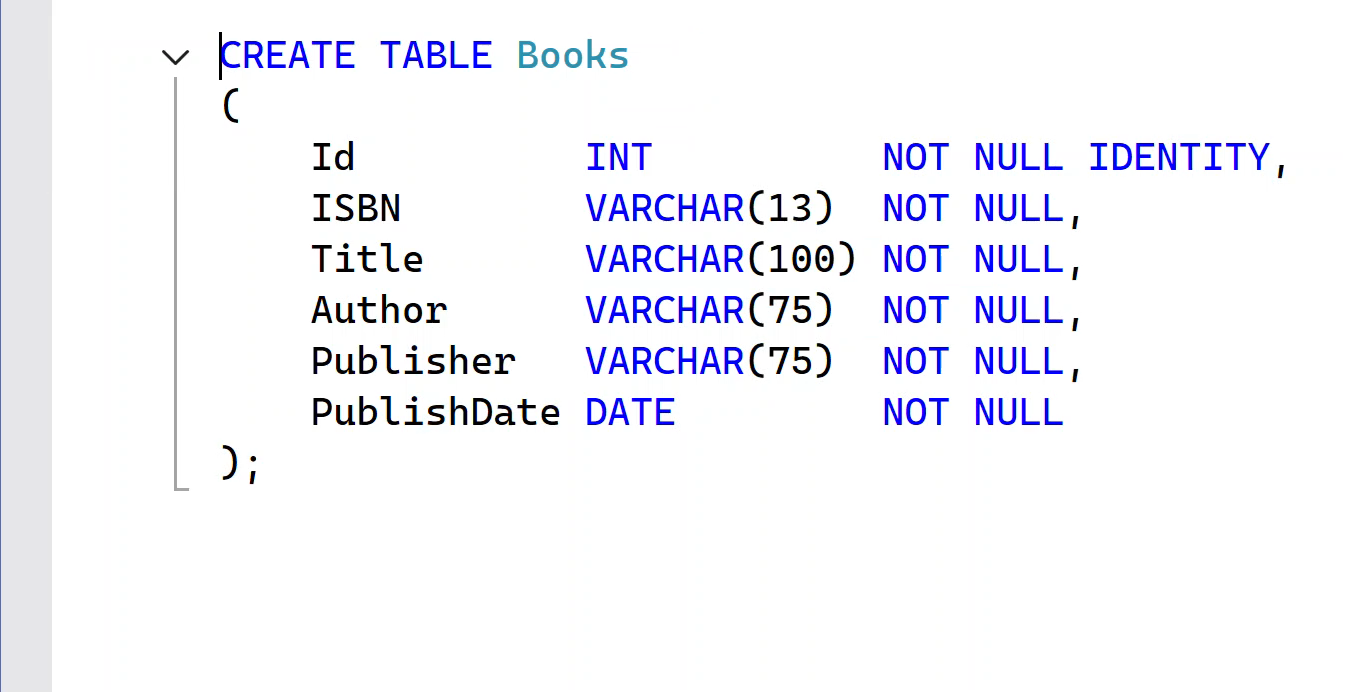 BLOG.JETBRAINS.COMSQL and NoSQL Query langauge support come to ReSharper!ReSharpers query language support for SQL and NoSQL provides C# developers with a more convenient way to work with SQL and NoSQL code directly in Visual Studio with ReSharper, supporting multiple SQL dialects beyond just T-SQL. It includes syntax highlighting, code analysis, auto-completion, and quick fixes to boost efficiency and catch issues early.Based on DataGripThe SQL and NoSQL support now available in ReSharper integrates with Visual Studios SQL editor. Visual Studio runs the query, but ReSharper is the tool that helps you write it. Whether youre doing DBA work or just querying a database, query language support in ReSharper goes along with your workflow just like other beloved JetBrains tools. Additionally, the query language features include formatting and quick fixes to give you a smooth and low-friction development experience. All these features are made possible because of the integration between ReSharper and DataGrip!Live templatesLive Templates are a powerful productivity feature that allows you to quickly insert commonly used code snippets or boilerplate snippets into your code. By typing a predefined abbreviation and pressing the Tab key, Live Templates expand into a block of useful code, saving time and reducing errors. While you code, ReSharper highlights relevant Live Templates by displaying an icon next to applicable code blocks. Live Templates are a great way to optimize your coding workflows. Here you can see both code completions and live templates in action.Code CompletionReSharpers code completion feature remains one of its most powerful tools for developers, and it continues to evolve with each release. ReSharper offers context-aware suggestions that adapt to the specifics of your database. ReSharpers code completion doesnt just save you time by predicting what you need; it actively helps reduce errors by understanding code structure, usage patterns, and project-specific nuances.Code completion works when youre creating SQL in C# strings too!Code inspectionsThis release features many SQL code inspections in ReSharper. While you code, look for the status indicators (blue squiggly underlines). When you encounter one, press Alt+Enter to show and then choose an option from the list of available intention actions.For example, SQL Server uses quoted identifiers to allow the use of reserved keywords or special characters as object names (e.g., column or table names) only by enclosing them in quotation marks or square brackets. If you try to use reserved keywords when creating or updating SQL objects, youll be notified so that they can be quoted for use.Code completion and inspections are effective because you can choose the SQL dialect to target the type of database youre using.NoSQL as well as SQLNoSQL support enables developers to work with non-relational databases such as MongoDB or Cassandra. Though these databases do not follow traditional RDBMS table structures, ReSharper provides many code completion and inspections for NoSQL databases. This makes working with unstructured or semi-structured data more efficient, bridging the gap between NoSQL systems and developer productivity.Configuration & SQL DialectsModern development databases are about more than just SQL Server. So weve included options to configure SQL & NoSQL, and theyre found under the Extensions | ReSharper | Options | SQL menu.General configuration optionsOnce in ReSharpers options dialog, you can set options to enable SQL syntax highlighting and SQL code inspections, and how SQL inspections integrate with Visual Studio. Navigate to Code Inspection | SQL | General to enable SQL syntax highlighting, SQL Code inspections, and more.SQL Dialects configurationReSharper might be a Visual Studio plugin, but we support more than just Microsofts T-SQL! You can choose the SQL dialect for the entire current solution, or choose custom dialects to apply to individual files or folders. Once you do so, ReSharper detects the dialect of SQL and then applies the appropriate inspections and quick fixes for that dialect. From within the options dialog, you can configure SQL Dialects by navigating to Code Inspection | SQL | SQL Dialects.Final NotesEmbrace your data! ReSharper integrates DataGrips SQL and NoSQL support into Visual Studio, providing features like syntax highlighting, code analysis, and auto-completion. It supports various SQL dialects and NoSQL databases like MongoDB and Cassandra, allowing configuration of database-specific settings. These features are available for DotUltimate subscribers only, however, you can download a trial version for individual ReSharper licenses.0 Σχόλια 0 Μοιράστηκε 3 Views
BLOG.JETBRAINS.COMSQL and NoSQL Query langauge support come to ReSharper!ReSharpers query language support for SQL and NoSQL provides C# developers with a more convenient way to work with SQL and NoSQL code directly in Visual Studio with ReSharper, supporting multiple SQL dialects beyond just T-SQL. It includes syntax highlighting, code analysis, auto-completion, and quick fixes to boost efficiency and catch issues early.Based on DataGripThe SQL and NoSQL support now available in ReSharper integrates with Visual Studios SQL editor. Visual Studio runs the query, but ReSharper is the tool that helps you write it. Whether youre doing DBA work or just querying a database, query language support in ReSharper goes along with your workflow just like other beloved JetBrains tools. Additionally, the query language features include formatting and quick fixes to give you a smooth and low-friction development experience. All these features are made possible because of the integration between ReSharper and DataGrip!Live templatesLive Templates are a powerful productivity feature that allows you to quickly insert commonly used code snippets or boilerplate snippets into your code. By typing a predefined abbreviation and pressing the Tab key, Live Templates expand into a block of useful code, saving time and reducing errors. While you code, ReSharper highlights relevant Live Templates by displaying an icon next to applicable code blocks. Live Templates are a great way to optimize your coding workflows. Here you can see both code completions and live templates in action.Code CompletionReSharpers code completion feature remains one of its most powerful tools for developers, and it continues to evolve with each release. ReSharper offers context-aware suggestions that adapt to the specifics of your database. ReSharpers code completion doesnt just save you time by predicting what you need; it actively helps reduce errors by understanding code structure, usage patterns, and project-specific nuances.Code completion works when youre creating SQL in C# strings too!Code inspectionsThis release features many SQL code inspections in ReSharper. While you code, look for the status indicators (blue squiggly underlines). When you encounter one, press Alt+Enter to show and then choose an option from the list of available intention actions.For example, SQL Server uses quoted identifiers to allow the use of reserved keywords or special characters as object names (e.g., column or table names) only by enclosing them in quotation marks or square brackets. If you try to use reserved keywords when creating or updating SQL objects, youll be notified so that they can be quoted for use.Code completion and inspections are effective because you can choose the SQL dialect to target the type of database youre using.NoSQL as well as SQLNoSQL support enables developers to work with non-relational databases such as MongoDB or Cassandra. Though these databases do not follow traditional RDBMS table structures, ReSharper provides many code completion and inspections for NoSQL databases. This makes working with unstructured or semi-structured data more efficient, bridging the gap between NoSQL systems and developer productivity.Configuration & SQL DialectsModern development databases are about more than just SQL Server. So weve included options to configure SQL & NoSQL, and theyre found under the Extensions | ReSharper | Options | SQL menu.General configuration optionsOnce in ReSharpers options dialog, you can set options to enable SQL syntax highlighting and SQL code inspections, and how SQL inspections integrate with Visual Studio. Navigate to Code Inspection | SQL | General to enable SQL syntax highlighting, SQL Code inspections, and more.SQL Dialects configurationReSharper might be a Visual Studio plugin, but we support more than just Microsofts T-SQL! You can choose the SQL dialect for the entire current solution, or choose custom dialects to apply to individual files or folders. Once you do so, ReSharper detects the dialect of SQL and then applies the appropriate inspections and quick fixes for that dialect. From within the options dialog, you can configure SQL Dialects by navigating to Code Inspection | SQL | SQL Dialects.Final NotesEmbrace your data! ReSharper integrates DataGrips SQL and NoSQL support into Visual Studio, providing features like syntax highlighting, code analysis, and auto-completion. It supports various SQL dialects and NoSQL databases like MongoDB and Cassandra, allowing configuration of database-specific settings. These features are available for DotUltimate subscribers only, however, you can download a trial version for individual ReSharper licenses.0 Σχόλια 0 Μοιράστηκε 3 Views -
Inside Ruby Debuggers: TracePoint, Instruction Sequence, and CRuby APIHello, Ruby developers!Debugging is a key part of software development, but most developers use debuggers without knowing how they actually work. The RubyMine team has spent years developing debugging tools for Ruby, and we want to share some of the insights weve gained along the way.In this post, well explore the main technologies behind Ruby debuggers TracePoint, Instruction Sequence, and Rubys C-level debugging APIs.Well begin with TracePoint and see how it lets debuggers pause code at key events. Then well build a minimal debugger to see it in action. Next, well look at Instruction Sequences to understand what Rubys bytecode looks like and how it works with TracePoint. Finally, well briefly cover Rubys C-level APIs and the extra power they offer.This blog post is the second in a series based on the Demystifying Debuggers talk by Dmitry Pogrebnoy, RubyMine Team Leader, presented at EuRuKo 2024 and RubyKaigi 2025. If you havent read the first post yet, its a good idea to start there. Prefer video? You can also watch the original talk here.Ready? Lets start!The core technologies behind any Ruby debuggerBefore diving into the debugger internals, its essential to understand the two core technologies that make Ruby debugging possible: TracePoint and Instruction Sequence. Regardless of which debugger you use, they all rely on these fundamental features built into Ruby itself. In the following sections, well explore how each of them works and why theyre so important.TracePoint: Hooking into Code ExecutionLets begin with TracePoint, a powerful instrumentation technology introduced in Ruby 2.0 back in 2013. It works by intercepting specific runtime events such as method calls, line executions, or exception raises and executing custom code when these events occur. TracePoint works in almost any Ruby context, and it works well with Thread and Fiber. However, it currently has limited support for Ractor.Lets take a look at the example and see how TracePoint works.def say_hello puts "Hello Ruby developers!"endTracePoint.new(:call) do |tp| puts "Calling method '#{tp.method_id}'"end.enablesay_hello# => Calling method 'say_hello'# => Hello Ruby developers!In this example, we have a simple say_hello method containing a puts statement, along with a TracePoint that watches events of the call type. Inside the TracePoint block, we print the name of the method being called using method_id. Looking at the output in the comments, we can see that our TracePoint is triggered when entering the say_hello method, and only after that do we see the actual message printed by the method itself.This example demonstrates how TracePoint lets you intercept normal code execution at specific points where special events occur, allowing you to execute your own custom code. Whenever your debugger stops on a breakpoint, TracePoint is in charge. This technology is valuable for more than just debugging. It is also used in performance monitoring, logging, and other scenarios where gaining runtime insights or influencing program behavior is necessary.Building the simplest Ruby debugger with TracePointWith just TracePoint technology, you can build what might be the simplest possible Ruby debugger youll ever see.def say_hello puts "Hello Ruby developers!"endTracePoint.new(:call) do |tp| puts "Call method '#{tp.method_id}'" while (input = gets.chomp) != "cont" puts eval(input) endend.enablesay_helloThis is almost the same code as in the TracePoint example, but this time the TracePoint code body is slightly changed.Lets examine whats happening here. The TracePoint block accepts user input via gets.chomp, evaluates it in the current context using the eval method, and prints the result with puts. Thats really all there is to it a straightforward and effective debugging mechanism in just a few lines of code.This enables one of the core features of a debugger the ability to introspect the current program context on each method invocation and modify the state if needed. You can, for example, define a new Ruby constant, create a class on the fly, or change the value of a variable during execution. Simple and powerful, right? Try to run it by yourself!Clearly, this isnt a complete debugger it lacks exception handling and many other essential features. But when we strip away everything else and look at the bare bones, this is the fundamental mechanism that all Ruby debuggers are built upon.This simple example demonstrates how TracePoint serves as the foundation for Ruby debuggers. Without TracePoint technology, it would be impossible to build a modern Ruby debugger.Instruction Sequence: Rubys bytecode revealedAnother crucial technology for Ruby debuggers is Instruction Sequence.Instruction Sequence, or iseq for short, represents the compiled bytecode that the Ruby Virtual Machine executes. Think of it as Rubys assembly language a low-level representation of your Ruby code after compilation into bytecode. Since its closely tied to the Ruby VM internals, the same Ruby code can produce a different iseq in different Ruby versions, not just in terms of instructions but even in their overall structure and relationships between different instruction sequences.Instruction Sequence provides direct access to the low-level representation of Ruby code. Debuggers can leverage this feature by toggling certain internal flags or even modifying instructions in iseq, effectively altering how the program runs at runtime without changing the original source code.For example, a debugger might enable trace events on a specific instruction that doesnt have one by default, causing the Ruby VM to pause when that point is reached. This is how breakpoints in specific language constructions and stepping through chains of calls work. The ability to instrument bytecode directly is essential for building debuggers that operate transparently, without requiring the developer to insert debugging statements or modify their code in any way.Lets take a look at how to get an Instruction Sequence in Ruby code.def say_hello puts "Hello Ruby developers !"endmethod_object = method(:say_hello)iseq = RubyVM::InstructionSequence.of(method_object)puts iseq.disasmLets examine this code more closely. First, we have our familiar say_hello method containing a puts statement. Then, we create a method object from it using method(:say_hello). Finally, we get the Instruction Sequence for this method and print out its human-readable form using disasm. This lets us peek under the hood and see the actual bytecode instructions that Ruby will execute.Lets examine the output and see what it looks like.== disasm: #&lt;ISeq:say_hello@iseq_example.rb:1 (1,0)-(3,3)>0000 putself ( 2)[LiCa]0001 putchilledstring "Hello Ruby developers !"0003 opt_send_without_block &lt;calldata!mid:puts, argc:1, FCALL|ARGS_SIMPLE>0005 leave ( 3)[Re]The first line shows metadata about our Ruby entity. Specifically, the say_hello method defined in iseq_example.rb with a location range (1,0)-(3,3). Below that are the actual instructions that the Ruby VM will execute. Each line represents a single instruction, presented in a human-readable format. You can easily spot the Hello Ruby developers ! string argument preserved exactly as it appears in the source code, without any encoding or decoding complexity, even with non-ASCII symbols. Such transparency makes it easier for you to understand whats happening at the bytecode level.Instruction Sequence plays a critical role in Ruby debugging by marking key execution points in the bytecode. In bracket notation in the output, you can notice markers like Li for line events, Ca for method calls, and Re for returns. These markers tell the Ruby VM when to emit runtime events. TracePoint relies on these markers to hook into the running program it listens for these events and steps in when they happen. This tight connection between two technologies is what makes it possible for debuggers to pause execution and inspect the state.Going deeper: Rubys C-level debugging APISo far, weve looked at the two core technologies behind Ruby debuggers TracePoint and Instruction Sequence. These are enough to build a working Ruby debugger. However, if you want to implement advanced features like those offered by RubyMine, such as smart stepping or navigating back and forth through the call stack, TracePoint and Instruction Sequence alone wont cut it. To support such capabilities, you need to go a level deeper and tap into the low-level debugging APIs provided by Ruby itself.CRuby exposes a number of internal methods that fill the gaps left by the public Ruby APIs. These methods are defined in C headers such as vm_core.h, vm_callinfo.h, iseq.h, and debug.h, among others. These internal interfaces can unlock powerful capabilities that go beyond whats possible with the public API, but they come with important trade-offs.Since they are specific to CRuby, debuggers using them wont work with other implementations like JRuby or TruffleRuby. Another downside is that these APIs are not public or stable across Ruby versions. Even minor updates can break them, which means any debugger depending on these methods needs constant attention to keep up with Rubys changes. Still, its worth exploring a few of these internal methods to get a better idea of what this low-level API looks like and what it provides for debugger tools.Lets start with rb_tracepoint_new(...):VALUE rb_tracepoint_new(VALUE target_thread_not_supported_yet, rb_event_flag_t events, void (*func)(VALUE, void *), void *data);This method works like creating a trace point in Ruby code, but with more flexibility for advanced use. Its especially helpful for low-level debuggers written as C extensions that need deeper access to the Ruby VM. In the RubyMine debugger, this approach allows more precise control over when and where to enable or disable trace points, which is essential for implementing smart stepping.Another useful method is rb_debug_inspector_open(...):VALUE rb_debug_inspector_open(rb_debug_inspector_func_t func, void *data);This C-level API lets you inspect the call stack without changing the VM state. The func callback receives a rb_debug_inspector_t struct, which provides access to bindings, locations, instruction sequences, and other frame details. In the RubyMine debugger, its used to retrieve the list of frames and implement the ability to switch between them back and forth on the call stack when the program is suspended by the debugger. Without this API, frame navigation and custom frame inspection in Ruby would be much more difficult.The final example is a pair of methods for working with iseq objects. The method rb_iseqw_to_iseq(...) converts an iseq from a Ruby value to a C value, while rb_iseq_original_iseq(...) converts it back from C to Ruby. These let Ruby debuggers switch between Ruby and C-extension code when precise, low-level control is needed. In the RubyMine debugger, they are actively used in the implementation of smart stepping, helping determine which code should be stepped into during debugging.These low-level APIs offer powerful tools for building advanced debugging features the kind that arent possible with TracePoint and Instruction Sequence alone. But they come with a cost: platform lock-in to CRuby and a high maintenance burden due to their instability across Ruby versions. Despite that, they remain essential for debuggers that need deep integration with the Ruby VM.ConclusionIn this post, we explored the foundational technologies that power Ruby debuggers TracePoint and Instruction Sequence. These two components form the basis for how modern Ruby debuggers observe and interact with running Ruby code. TracePoint enables hooks into specific runtime events like method calls and line execution, while Instruction Sequence provides low-level access to the compiled Ruby VM bytecode.We also took a brief look at how low-level CRuby C APIs exert even more precise control over code execution, offering insight into how debuggers like RubyMine implement advanced features. While we didnt dive into full debugger implementations here, this foundation lays the groundwork for understanding how these tools operate.Stay tuned in a future post, well go further into how modern debuggers are built on top of this foundation.Happy coding, and may your bugs be few and easily fixable!The RubyMine team0 Σχόλια 0 Μοιράστηκε 6 Views
-
Get Answers to Your KMP QuestionsDuring the Closing Panel at KotlinConf 2025, we received many questions about Kotlin Multiplatform (KMP), but unfortunately didnt have time to address them all live. So weve decided to answer the most popular ones in a follow-up blog post.Will IntelliJ IDEA and Android Studio support full Swift navigation, completion, etc., for iOS code, or is that not feasible because of Apple restrictions?The KMP plugin for IntelliJ IDEA and Android Studio already supports Swift and cross-language Kotlin/Swift features such as navigation, and we plan to add more! Check out this blog post to learn more.Whats the Kotlin teams plan to improve the native compilation speed (desktop targets) for multiplatform projects? Waiting 10 minutes to compile a small CLI app is not acceptable for many teams.We are currently looking into native build performance. First, please check our recommendations on improving native compilation speed. If they dont help, we would highly appreciate it if you could file a bug report and provide more details about the project. It would give us valuable insights on how to address the performance issues.How do you see KMP evolving over the next year?We are driving Kotlin Multiplatform towards a complete and mature solution! We have big plans for Compose Multiplatform and are working on the Beta of Compose Multiplatform for web. In addition to UI sharing, well be improving business logic sharing scenarios, focusing on Kotlin/JS with @JsExport and Kotlin/Native Swift export. Check out our plans for the web platform in general. As we have just released the first version of the KMP plugin for IntelliJ IDEA and Android Studio, we plan to work on its stability and bring more productivity features, which you can find details about in this blog post.Check out the KMP roadmap to learn more.Can you please elaborate on the work being done to improve web support for Compose/KMP?We are working on the Beta of Compose Multiplatform for web. We have already provided more APIs to ensure parity with other platforms, such as clipboard and dragndrop, collaborated with browser vendors to improve the performance of web apps, and improved the pointer and text input behavior.For the Beta of Compose Multiplatform for web, we plan to add interop with HTML elements, compatibility mode for older browsers with automatic fallback to JS, a prototype for accessibility support, and multiple improvements to key UI components.Are there any plans to support accessibility and SEO in Compose Multiplatform for Web, when everything renders to pixels in a canvas?We plan to implement basic accessibility support by mapping Compose semantics nodes to DOM elements later this year. Having the backing DOM hierarchy on a page would allow for some SEO support too. SEO can be further improved by pre-rendering the content as DOM on the server side, but we havent investigated this yet.Why does Compose Multiplatform have scrollbars, while Android Jetpack Compose does not?Scrollbars were first implemented for the desktop target, but we are exploring how to bring them to other platforms.Are we getting Navigation 3 for KMP?Navigation 3 has been built with Kotlin Multiplatform in mind. So, the answer is yes, there will be multiplatform support for Navigation 3. However, we dont know when, as it depends on other ongoing work. Please follow the corresponding YouTrack ticket for further updates.0 Σχόλια 0 Μοιράστηκε 21 Views
-
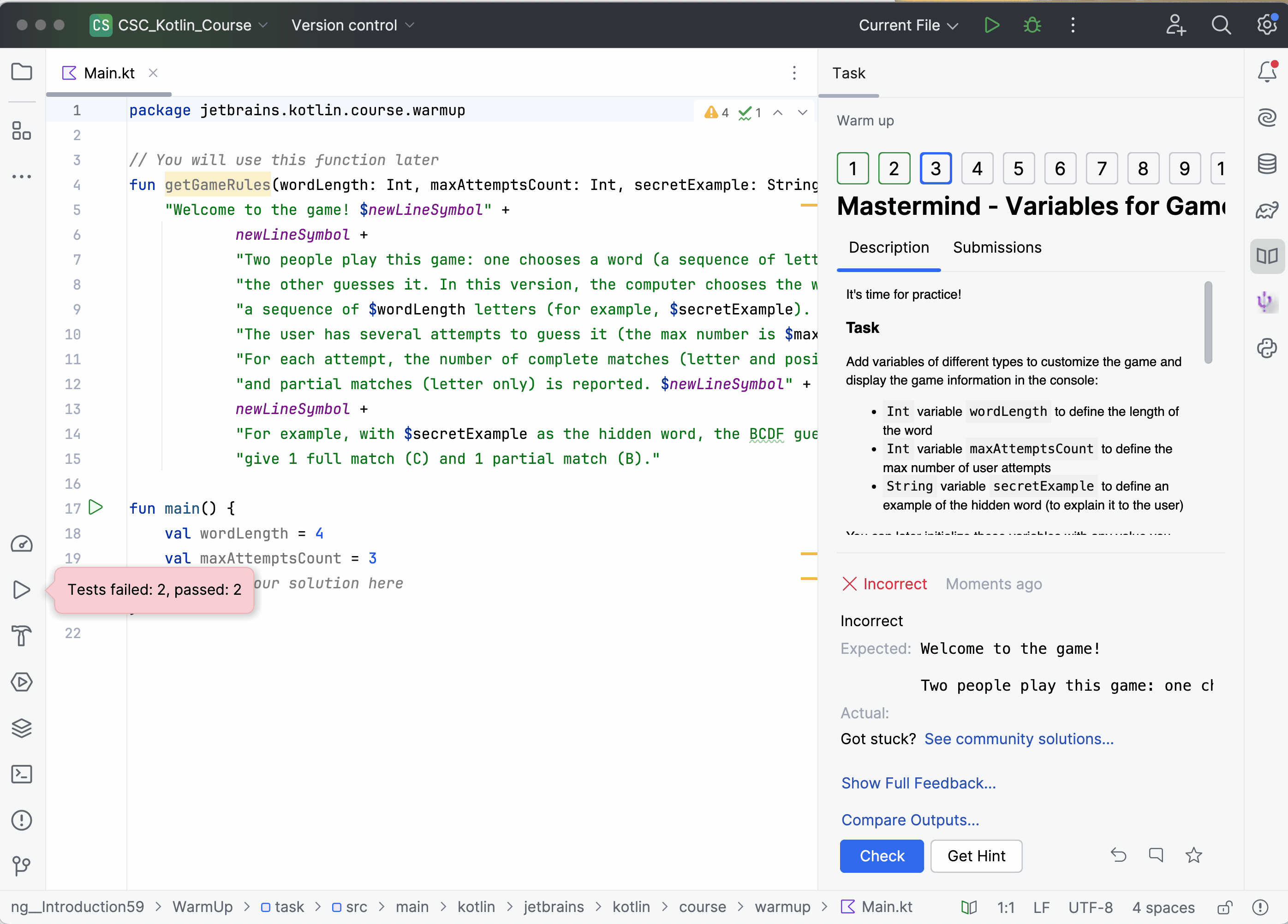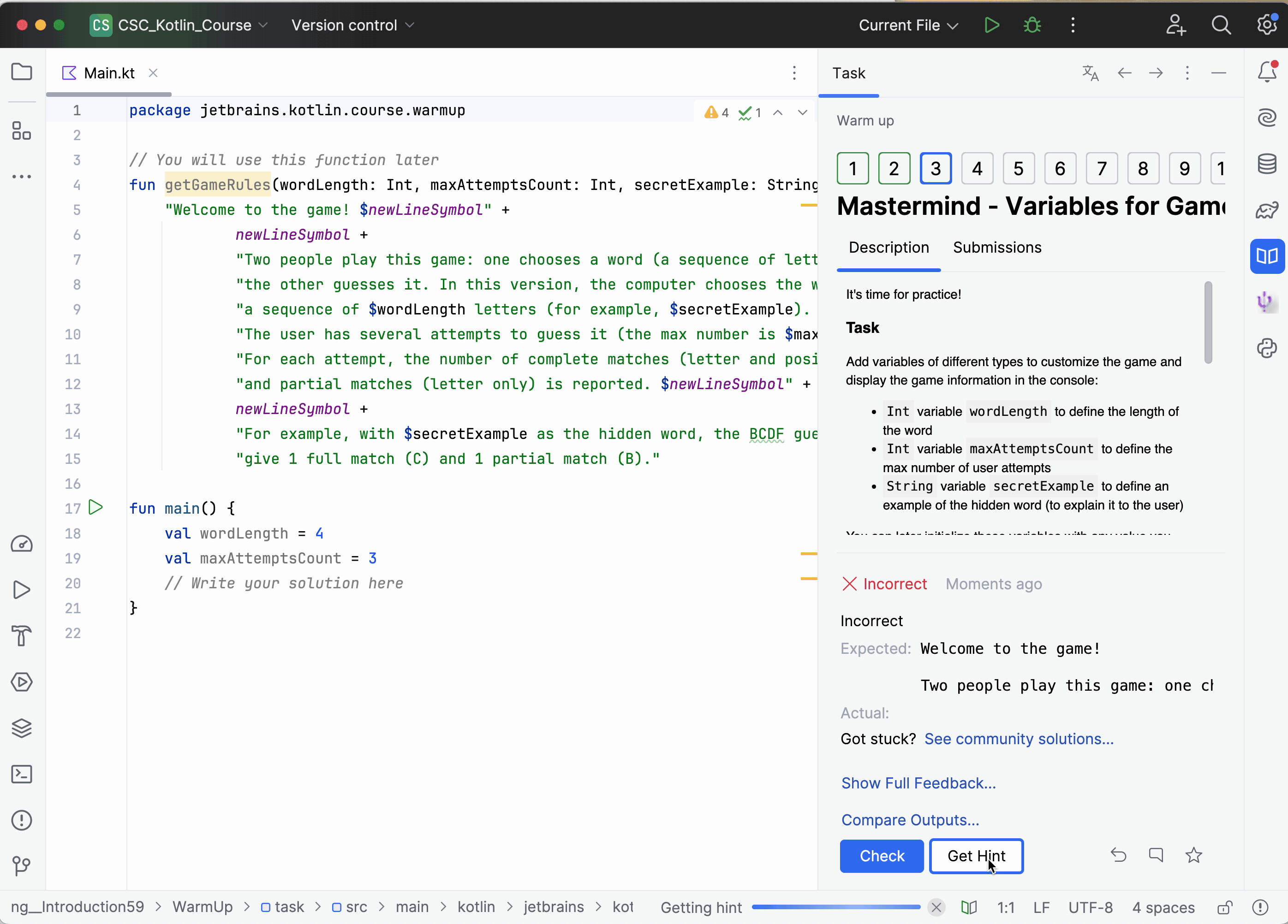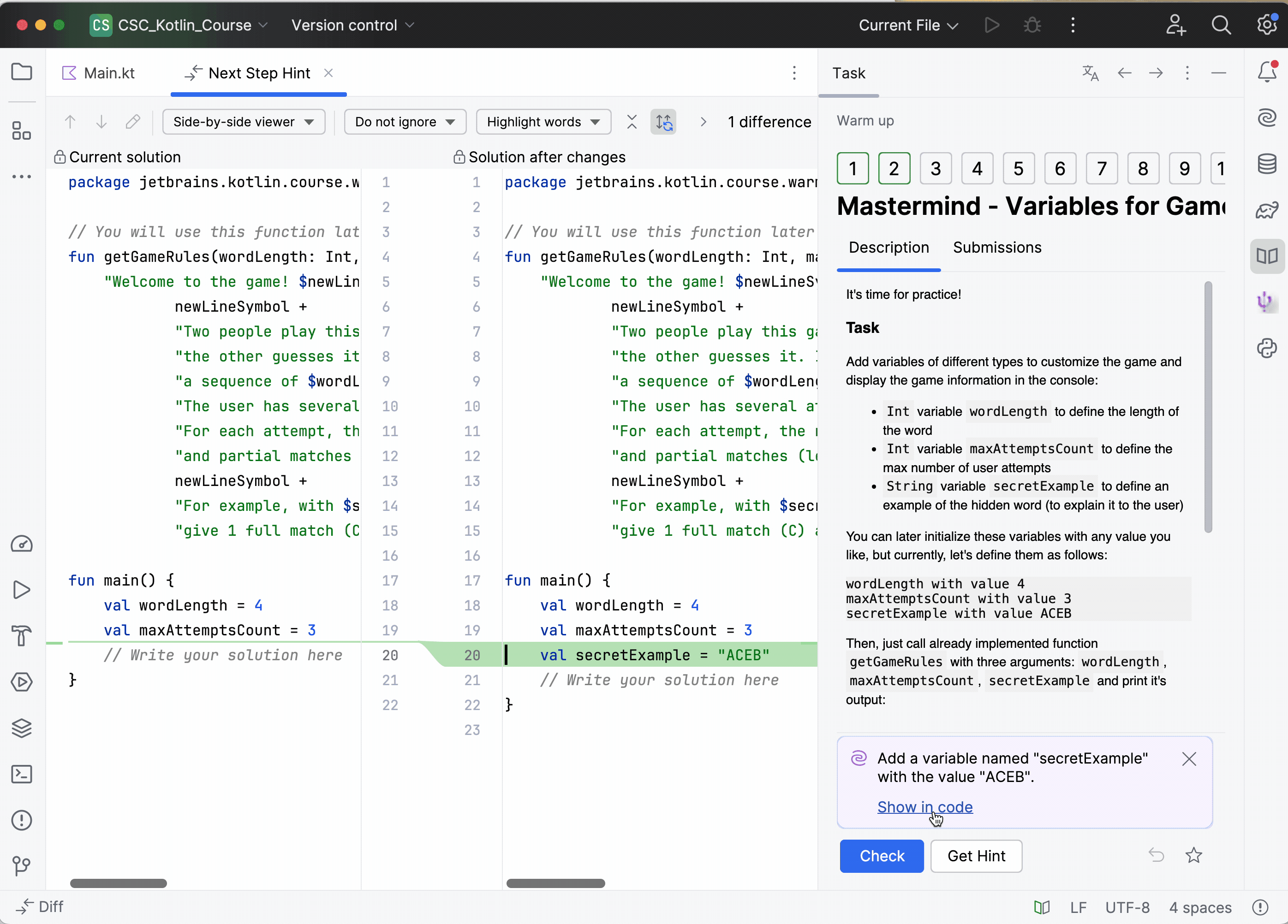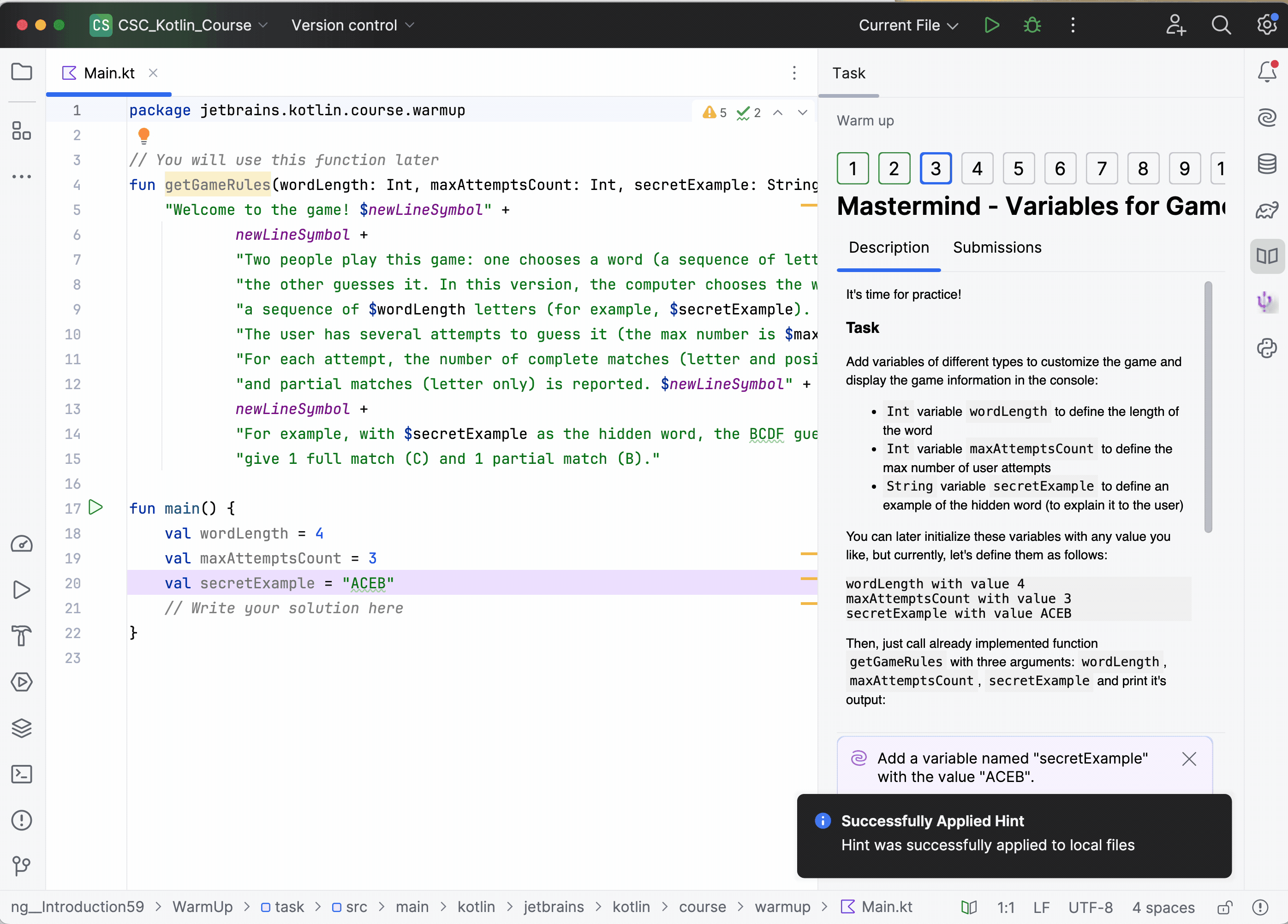 BLOG.JETBRAINS.COMAI-Powered Learning, Part 2: Get Unstuck With AI Hints in Python and Kotlin TasksIn our previous post, we introduced AI-powered machine translation and inline theory definitions to help make learning smoother and more accessible. Today, were excited to share the next big step in bringing intelligent assistance to your programming journey: AI hints.This feature is designed especially for beginners who may get stuck while solving coding tasks unsure how to move forward, fix a failing test, or resolve a compilation error. With AI hints, the JetBrains Academy plugin is here to guide you, one step at a time.To explore the latest improvements, install the JetBrains Academy plugin or update to the latest version from Settings/Preferences | Plugins in your JetBrains ID. INSTALL FREE PLUGIN How AI hints workWhen youre solving a programming task in Python or Kotlin, youll now see a new option to request an AI hint. The hint is delivered in two parts:A text explanation describing what you could do next.A code diff preview showing the suggested change right inside your IDE.This way, you not only get the answer you also learn how to arrive at it.An example of an AI-generated next step hint in a Kotlin taskWhat can AI hints help with?The current version of AI hints supports:Suggestions for the next logical step if youre stuck solving a task.Fixes for compilation errors.Hints to help pass failing tests.These hints combine static code analysis from your IDE with the power of large language models (LLMs), bringing together the best of both worlds deep context awareness and intelligent language understanding.A note on accuracyAI-generated hints are still evolving. They may occasionally be incomplete or inaccurate, especially in more complex scenarios. But weve built in an easy way to help us improve: just use the Feedback button after seeing a hint. Your input directly contributes to making the system smarter and more helpful over time.Where to find itAI hints are currently available for programming tasks in Python and Kotlin in all IDE-based Marketplaces courses.To try out AI hints:Open a Python or Kotlin course.Start solving a programming task.If youre stuck, click the Get Hint button.See what to do next and how to do it.We hope AI hints make learning to code feel more approachable and less frustrating.Have any feedback or questions? Drop us a comment below or submit feedback right from the plugin.Happy learning!The JetBrains Academy team0 Σχόλια 0 Μοιράστηκε 21 Views
BLOG.JETBRAINS.COMAI-Powered Learning, Part 2: Get Unstuck With AI Hints in Python and Kotlin TasksIn our previous post, we introduced AI-powered machine translation and inline theory definitions to help make learning smoother and more accessible. Today, were excited to share the next big step in bringing intelligent assistance to your programming journey: AI hints.This feature is designed especially for beginners who may get stuck while solving coding tasks unsure how to move forward, fix a failing test, or resolve a compilation error. With AI hints, the JetBrains Academy plugin is here to guide you, one step at a time.To explore the latest improvements, install the JetBrains Academy plugin or update to the latest version from Settings/Preferences | Plugins in your JetBrains ID. INSTALL FREE PLUGIN How AI hints workWhen youre solving a programming task in Python or Kotlin, youll now see a new option to request an AI hint. The hint is delivered in two parts:A text explanation describing what you could do next.A code diff preview showing the suggested change right inside your IDE.This way, you not only get the answer you also learn how to arrive at it.An example of an AI-generated next step hint in a Kotlin taskWhat can AI hints help with?The current version of AI hints supports:Suggestions for the next logical step if youre stuck solving a task.Fixes for compilation errors.Hints to help pass failing tests.These hints combine static code analysis from your IDE with the power of large language models (LLMs), bringing together the best of both worlds deep context awareness and intelligent language understanding.A note on accuracyAI-generated hints are still evolving. They may occasionally be incomplete or inaccurate, especially in more complex scenarios. But weve built in an easy way to help us improve: just use the Feedback button after seeing a hint. Your input directly contributes to making the system smarter and more helpful over time.Where to find itAI hints are currently available for programming tasks in Python and Kotlin in all IDE-based Marketplaces courses.To try out AI hints:Open a Python or Kotlin course.Start solving a programming task.If youre stuck, click the Get Hint button.See what to do next and how to do it.We hope AI hints make learning to code feel more approachable and less frustrating.Have any feedback or questions? Drop us a comment below or submit feedback right from the plugin.Happy learning!The JetBrains Academy team0 Σχόλια 0 Μοιράστηκε 21 Views -
BLOG.JETBRAINS.COMHelp Predict the Future of AI in Software Development!Ever wanted to share your ideas about AI and have a chance at winning prizes at the same time? As a company dedicated to creating the best possible solutions for software development, we at JetBrains want to know what you think about AI in software development. Participate in our tournament! In this post, we tell you more about the tournament and offer tips for making accurate predictions. And in case youre new to forecasting platforms, weve included an overview below.Lets get started so that you can add your voice to community-sourced forecasting!JetBrains Researchs AI in Software Development 2025 tournamentTo participate in the tournament, all you have to do is register on Metaculus and complete this short survey .Make sure to input your predictions before the resolution on December 1, 2025!Tournament specsWith this forecasting challenge, we are primarily interested in seeing how accurately participants can predict emerging AI features in software development.We also want to understand:Developers attitudes about AI and how they are evolvingIndividual features of the best forecastersHow people estimate the future of various benchmarksCurrently, the tournament includes 13 questions. To keep everything fair, we have invited independent experts to review the questions and to evaluate the end resolutions. These experts are:Olga Megorskaya, Chief Executive Officer at TolokaGrigory Sapunov, Co-Founder and CTO at IntentoIftekhar Ahmed, Associate Professor at the University of California, IrvineHussein Mozannar, Senior Researcher at Microsoft Research AI FrontiersDmitiry Novakovskiy, Head of Customer Engineering at Google CloudRankings and the prize poolIn this tournament, your ranking will be calculated based on your peer score.Generally speaking, a positive score indicates higher accuracy, and a negative score lower (how exactly Metaculus calculates the peer score). A bit more specifically, the ranking is calculated from the sum of your peer scores over all the questions, which are individually weighted. That is, if you do not forecast a specific question, you score zero on that question.For the AI in Software Development 2025 Tournament, we have a USD 3,000 prize pool, which will be distributed across the first three leaderboard medals as follows (all prizes in USD):First place: $1,500Second place: $1,000Third place: $500Note that in order to be eligible for the prize pool, you must fill out the quick research survey!Tips for making accurate predictions on forecasting platformsHere are some tips to get you on the path to positive peer scores and higher rankings:Consider alternative scenarios before placing your forecast. This is generally a good idea, but also very useful if the event concerns something novel or very uncertain.Ongoing news can inform the probabilities of different outcomes, so stay informed!Be careful of being overconfident. Besides considering alternatives, it is useful to list offline the reasons why your forecast could be wrong.As with many skills, practicing helps. Especially on a platform like Metaculus, when practicing forecasting, you can improve by posting your reasoning in the discussion section and reading about other participants reasoning.If you have forecasted a few questions as practice, compare your track record with the community track record. (But dont only predict based on the community median. Your insights and evidence are valuable, too!)For more resources, check out Metaculus collection of analysis tools, tutorials, research literature, and tips, as well as their forecasting guide for each type of question.Online forecasting tools: a primerWhat are online forecasting tools? Via a combination of user inputs and sophisticated statistical modelling, these tools enable the prediction of future events.If youve never heard of forecasting platforms before, you might guess that they are like gambling sites. While there are some similarities with betting, online forecasting tools are not strictly synonymous with gambling, whether online or at the tracks. A crucial difference is that forecasting tools are used by people interested in gathering information about future events, not necessarily (or solely) to gain a profit based on the outcome of a future event. In particular, our forecasting tournament focuses on evaluating the prediction skills of participants; the prizes are merely perks for the top-ranked forecasters and an exception to most queries on the hosting platform Metaculus.Another type of information-gathering tool is a poll or a survey. While similar in empirical intent, the questions in polls often ask about participants (a) experiences, (b) ideas, or (c) preferences and not about tangible, objective facts that can be unambiguously resolved. Here are some real-world examples from YouGov (UK): (a) whether the participants have watched political content on TikTok, (b) participants views on banning phones in schools, and (c) which Doctor Who version the participant prefers.While there might be a clear winner among the respondents, the results will reflect peoples preferences and thoughts, sometimes about facts, but the results are not facts themselves. Likewise, any survey results are subject to differences among varying demographics.For the survey question (b), there is a clear winner in the results below, but this is only the opinion of the people in the UK who were asked. And while the respondent may be interested in the results (e.g. they really want schools to ban phones), there is no direct gain for having given a more popular or more accurate response. Source: YouGov plc, 2025, All rights reserved. [Last access: May 22, 2025]In contrast, a forecasting querys responses are evaluated for accuracy against facts at the time of resolution. Those participating are actively interested in the resolution, as it affects leaderboard prestige and/or financial reward, depending on the type of forecasting platform. This also means that participants are more motivated to give what they think are accurate predictions, even if it does not 100% align with their personal preferences at the time.Often forecasting platforms involve binary questions, like in Will DeepSeek be banned in the US this year?. The queries can also be about uncertain events with multiple possible outcomes, e.g. for the winner of Eurovision 2025, where until the finals, many countries have a chance. Similarly, queries with numerical ranges, such as in the prediction of the Rotten Tomatoes score of Mission: Impossible The Final Reckoning, can consider the weight of different ranges. Even if different platforms architectures handle the calculations slightly differently, the main takeaway is that there are resolution deadlines and that the event in question can be unambiguously resolved on forecasting platforms. See the figure below for a snapshot of the rules summary for the Mission: Impossible question on Kalshi.Source: Kalshi. [Last access: May 22, 2025]The following subsections present the history of forecasting tools, including the most common kinds and which one is relevant for this forecasting challenge.A history of predictionForecasting mechanisms have existed informally for centuries, where people could predict outcomes like papal or presidential election results. More formal forecasting tools were established at the end of the 20th century, starting with a similar focus, and have since gained currency while expanding their application.Well-known examples of formal forecasting mechanisms include the Iowa Electronic Market, created as an experimental tool in 1988 for the US presidential elections popular vote, still in use today; Robin Hansons paper-based market, created in 1990 for Project Xanadu employees to make predictions on both the companys product and scientific controversies; and the online Hollywood Stock Exchange, established in 1996 as a way for participants to bet on outcomes in the entertainment industry.These forecasting tools demonstrated how much more accurate aggregated predictions can be than individual ones (see for example The Wisdom of Crowds or Anatomy of an Experimental Political Stock Market), motivating economists to take their insights seriously. Around the same time, big companies such as Google, Microsoft, and Eli Lily began establishing company-internal prediction markets. These days, many companies have their internal prediction tools; for example, we at JetBrains recently launched our own platform, called JetPredict.For example, Googles internal product, Prophit, was launched in 2005 and offered financial incentives, plus leaderboard prestige, to employees best at predicting. Although an internal product, Prophit was known outside of Google as a prediction platform demonstrating relatively high accuracy. It eventually had to shut down in the late 2000s, due to federal regulations (and the 2008 financial crisis did not help either). Many publications covered this topic at the time, for example this 2005 NYTimes article At Google, the Workers are Placing their Bets, this 2007 Harvard Business Case Study Prediction Markets at Google, and the 2008 article Using Prediction Markets to Track Information Flows: Evidence from Google. More recently, there was an article about Prophit and a second internal market, Gleangen: The Death and Life of Prediction Markets at Google. Beyond big corporations, researchers have started using formal prediction tools to predict things like study replicability, a crucial scientific tenet. In a comparison of forecasting tools and survey beliefs predicting this, the former were much more accurate than the latter. If you are interested, The Science Prediction Market Project provides a collection of papers on the topic. Applying forecasting tools to research is still less widespread than forecasting in the business world, but its an exciting space to watch!Different forecasting tools todayNot all forecasting platforms are prediction markets, even if the terms are sometimes used interchangeably. Here we only look at overall differences without going into detail of, say, kinds of prediction markets or the math behind the models.If you are interested, here are further resources on these differences provided by WIFPR, Investopedia, and the Corporate Finance Institute.The hallmark of a prediction market is that participants are offered financial incentives by way of event contracts, sometimes also called shares. Key concepts include:The event contracts can be sold or bought depending on the participants belief in the outcome.The current price reflects what the broader community expects of the outcome.As the nominal contract values are typically USD 1, the sum of the share prices is USD 1 as well. So, for a markets implied probability of about 60%, the average share price to buy will be around 60 cents.Prices change in real-time as new information emerges.If the participant bought contract shares for the correct prediction, they earn money (USD 1 typically) for each share purchased. Incorrect predictions mean no money is earned.Translating those concepts into an example: A question on the prediction market Kalshi asks whether Anthropic will release Claude 4 before June 1, 2025. At the time of writing this post, the likelihood of Claude 4s release was at 34% according to the community, as shown in the figure below.Source: Kalshi. [Last access: May 16, 2025, 17:25 CEST]If you wanted to participate in the above market on May 16, the following scenarios could have occurred. If you believed the release would have happened before June 1, you could have bought shares for about 35 cents each. Say you bought 100 shares for USD 35 and, come June 1, Anthropic did indeed release Claude 4. You would then have won USD 100 (USD 1 multiplied by 100 shares), and your profit would be USD 65 (USD 100 win minus your USD 35 investment). If Anthropic did not release Claude 4 by June 1, you would then have lost your initial USD 35 investment.The figure above additionally shows that earlier in the year, the community thought that Claude 4 was more likely to be released by the resolution date. As more evidence rolls in, the outcomes likelihood can change.Aggregating community forecasts is also possible without share-buying and profit-seeking. Other forecasting platforms, such as Good Judgement or Metaculus, use a broader toolset for their prediction architecture, focusing primarily on leveraging collective intelligence and transparent scoring. By eliminating profit as the primary incentive and instead rewarding forecasters for their prediction accuracy over time, extreme predictions are discouraged.In particular, Metaculus is building a forecasting ecosystem with a strong empirical infrastructure, using techniques such as Bayesian statistics and machine learning. This creates a platform that is overall more cooperative and has a shared scientific intent. The platform encourages participants to publish the reasoning behind their picks, which fosters community discussions.Accuracy and the broader impact of community-sourced forecastingAs forecasting tools become more sophisticated, they are also getting more accurate in their predictions. In its current state, Metaculus already outperforms notoriously robust statistical models, as was recorded in Forecasting skill of a crowd-prediction platform: A comparison of exchange rate forecasts. The platform additionally keeps an ongoing record of all resolved questions with performance statistics.Metaculus is a platform that not only benefits from community inputs, but also provides vital information to the community. Take the COVID-19 pandemic for example: predictors on Metaculus accurately anticipated the impact of the virus before it was globally recognized as a pandemic. In turn, the insights on specific events within such a pandemic can be valuable to policymakers, like in this case study on an Omicron wave in the US.Researchers are continuously investigating various public health threats. An open question at the time of writing, on the possibility of the avian influenza virus becoming a public health emergency, is shown in the figure below. What would be your prediction?Source: Metaculus. [Last access: May 16, 2025]At JetBrains, our commitment goes beyond delivering top-tier software development solutions and innovative AI tools: We are passionate about nurturing a vibrant, engaged community and creating meaningful opportunities for learning and collaboration. We believe that open dialogue about the future of AI in software development is essential to advancing the field.With these shared values, we are proud to partner with Metaculus as the host for our forecasting challenge. Together, we look forward to inspiring thoughtful discussion, driving progress, and shaping the future of AI in software development.0 Σχόλια 0 Μοιράστηκε 26 Views
-
Context Collection Competition by JetBrains and Mistral AIBuild smarter code completions and compete for a share of USD 12,000!In AI-enabled IDEs, code completion quality heavily depends on how well the IDE understands the surrounding code the context. That context is everything, and we want your help to find the best way to collect it.Join JetBrains and Mistral AI at the Context Collection Competition. Show us your best strategy for gathering code context, and compete for your share of USD 12,000 in prizes and a chance to present it at the workshop at ASE 2025.Why context mattersCode completion predicts what a developer will write next based on the current code. Our experiments at JetBrains Research show that context plays an important role in the quality of code completion. This is a hot topic in software engineering research, and we believe its a great time to push the boundaries even further.Goal and tracksThe goal of our competition is to create a context collection strategy that supplements the given completion points with useful information from across the whole repository. The strategy should maximize the chrF score averaged between three strong code models: Mellum by JetBrains, Codestral by Mistral AI, and Qwen2.5-Coder by Alibaba Cloud.The competition includes two tracks with the same problem, but in different programming languages:Python: A popular target for many novel AI-based programming assistance techniques due to its very wide user base.Kotlin: A modern statically-typed language with historically good support in JetBrains products, but with less interest in the research community.Were especially excited about universal solutions that work across both dynamic (Python) and static (Kotlin) typing systems.PrizesEach track awards prizes to the top three teams: 1st place: USD 3,000 2nd place: USD 2,000 3rd place: USD 1,000Thats a USD 12,000 prize pool, plus free ASE 2025 workshop registration for a representative from each top team.Top teams will also receive: A one-year JetBrains All Products Pack license for every team member (12 IDEs, 3 extensions, 2 profilers; worth USD 289 for individual use). USD 2,000 granted on La Plateforme, for you to use however you like.Join the competitionThe competition is hosted on Eval.AI. Get started here: https://jb.gg/co4.We have also released a starter kit to help you hit the ground running: https://github.com/JetBrains-Research/ase2025-starter-kit.Key dates are:June 2, 2025: competition opensJune 9, 2025: public phase beginsJuly 25, 2025: public phase endsJuly 25, 2025: private phase beginsJuly 25, 2025: solution paper submission opensAugust 18, 2025: private phase endsAugust 18, 2025: final results announcedAugust 26, 2025: solution paper submission closesNovember 2025: solutions presented at the workshopBy participating in the competition, you indicate your agreement to its terms and conditions.0 Σχόλια 0 Μοιράστηκε 26 Views
-
 BLOG.JETBRAINS.COMJunie and RubyMine: Your Winning ComboJunie, a powerful AI coding agent from JetBrains, is available in RubyMine! Install the plugin and try it out now!Why Junie is a game-changerUnlike other AI coding agents, Junie leverages the robust power of JetBrains IDEs and reliable large language models (LLMs) to deliver exceptional results with high precision.According to SWE-bench Verified, a curated benchmark of 500 real-world developer tasks, Junie successfully solves 60.8% of tasks on a single run. This impressive success rate demonstrates Junies ability to tackle coding challenges that would normally require hours to complete. This is more than AI its the latest evolution in developer productivity.Your most trusted AI partnerJunie isnt just an assistant its your creative and strategic partner. Heres what Junie can do for you in RubyMine:Build entire Ruby apps, not just snippetsNeed more than individual code fragments? Junie can write entire applications, handling complex structures with ease and precision.Automate inspections and testingPairing Junie with RubyMines powerful code insight tools means inspections and automated tests (RSpec, minitest) are no longer a chore. Let Junie ensure your code works and works well.Suggest features and code improvementsStuck? Junie brings fresh ideas to the table, pointing out areas for improvement, suggesting optimizations, or brainstorming entirely new features for your project.Clean and align code with your styleJunie doesnt just write code it ensures everything aligns with your coding style and guidelines, leaving your code polished, structured, and ready to deploy.With most of the heavy lifting off your plate, Junie saves you time and mental energy. Instead of getting bogged down in the mundane, youre free to focus on strategy, innovation, and big-picture ideas.You define the process, Junie elevates itWhile Junie is indeed powerful and capable, its designed to enhance your coding experience, not take control of it. You remain the decision-maker at every step from delegating tasks to reviewing Junies code suggestions.You control how and when AI contributes to your workflow. No matter what you entrust to Junie, it will adapt to your style and always give you the final say, ensuring that your code remains truly yours.Try Junie in RubyMine todayNow is the perfect time to try Junie in RubyMine and experience firsthand how AI can boost your productivity, simplify your workflow, and enhance your coding experience.To install Junie in RubyMine, visit this page.Follow us for updates and tipsFind more about Junie and the projects further development inthis article.Stay connected through our official RubyMine X channel. Dont forget to share your thoughts in the comments below and to suggest and vote for new features in our issue tracker.Happy developing!The RubyMine team0 Σχόλια 0 Μοιράστηκε 27 Views
BLOG.JETBRAINS.COMJunie and RubyMine: Your Winning ComboJunie, a powerful AI coding agent from JetBrains, is available in RubyMine! Install the plugin and try it out now!Why Junie is a game-changerUnlike other AI coding agents, Junie leverages the robust power of JetBrains IDEs and reliable large language models (LLMs) to deliver exceptional results with high precision.According to SWE-bench Verified, a curated benchmark of 500 real-world developer tasks, Junie successfully solves 60.8% of tasks on a single run. This impressive success rate demonstrates Junies ability to tackle coding challenges that would normally require hours to complete. This is more than AI its the latest evolution in developer productivity.Your most trusted AI partnerJunie isnt just an assistant its your creative and strategic partner. Heres what Junie can do for you in RubyMine:Build entire Ruby apps, not just snippetsNeed more than individual code fragments? Junie can write entire applications, handling complex structures with ease and precision.Automate inspections and testingPairing Junie with RubyMines powerful code insight tools means inspections and automated tests (RSpec, minitest) are no longer a chore. Let Junie ensure your code works and works well.Suggest features and code improvementsStuck? Junie brings fresh ideas to the table, pointing out areas for improvement, suggesting optimizations, or brainstorming entirely new features for your project.Clean and align code with your styleJunie doesnt just write code it ensures everything aligns with your coding style and guidelines, leaving your code polished, structured, and ready to deploy.With most of the heavy lifting off your plate, Junie saves you time and mental energy. Instead of getting bogged down in the mundane, youre free to focus on strategy, innovation, and big-picture ideas.You define the process, Junie elevates itWhile Junie is indeed powerful and capable, its designed to enhance your coding experience, not take control of it. You remain the decision-maker at every step from delegating tasks to reviewing Junies code suggestions.You control how and when AI contributes to your workflow. No matter what you entrust to Junie, it will adapt to your style and always give you the final say, ensuring that your code remains truly yours.Try Junie in RubyMine todayNow is the perfect time to try Junie in RubyMine and experience firsthand how AI can boost your productivity, simplify your workflow, and enhance your coding experience.To install Junie in RubyMine, visit this page.Follow us for updates and tipsFind more about Junie and the projects further development inthis article.Stay connected through our official RubyMine X channel. Dont forget to share your thoughts in the comments below and to suggest and vote for new features in our issue tracker.Happy developing!The RubyMine team0 Σχόλια 0 Μοιράστηκε 27 Views -
 BLOG.JETBRAINS.COMWhats Next for RubyMineHello everyone!The RubyMine 2025.2 Early Access Program is already available! In this blog post, well share the upcoming features and updates planned for this release cycle.Whats coming in RubyMine 2025.2?Debugger improvementsWere introducing a number of changes aimed at enhancing the debugger installation experience. The entire process will now take less time, and the associated notifications will be less distracting and more informative. Finally, the RubyMine debugger will be updated to support newly released Ruby versions sooner than it previously did.Better multi-module supportA priority of the upcoming RubyMine release is the provision of support for multi-module projects. This will include bundler improvements, faster startup for multi-module projects, smoother switching between interpreters, and more.Automatic management of RBS CollectionWe made this feature a default setting, which requires RBS 3.2. Ruby 3.4 comes with a compatible RBS version bundled. This is beneficial for all features related to code insight.Better remote development experienceWe are continuing to enhance RubyMine remote development as an alternative to using just remote Ruby interpreters. In 2025.2, you will enjoy an even better overall performance and several improvements to split mode.AI Assistant improvementsIn the new release, you can expect AI Assistant to generate more code suggestions across your projects. The quality of multi-line suggestions will also improve now that the formatting of outputs has been fixed.Whats more, in line with our efforts to expand AI Assistants functionality, we have improved code completion for ERB in RubyMine 2025.2.Join the Early Access ProgramYou can download the latest EAP build from our website or via the Toolbox App. The full list of tickets addressed by this EAP build is available in the release notes.Stay connected through our official RubyMine X channel. We encourage you to share your thoughts in the comments below and to create and vote for new feature requests in our issue tracker.Happy developing!The RubyMine team0 Σχόλια 0 Μοιράστηκε 26 Views
BLOG.JETBRAINS.COMWhats Next for RubyMineHello everyone!The RubyMine 2025.2 Early Access Program is already available! In this blog post, well share the upcoming features and updates planned for this release cycle.Whats coming in RubyMine 2025.2?Debugger improvementsWere introducing a number of changes aimed at enhancing the debugger installation experience. The entire process will now take less time, and the associated notifications will be less distracting and more informative. Finally, the RubyMine debugger will be updated to support newly released Ruby versions sooner than it previously did.Better multi-module supportA priority of the upcoming RubyMine release is the provision of support for multi-module projects. This will include bundler improvements, faster startup for multi-module projects, smoother switching between interpreters, and more.Automatic management of RBS CollectionWe made this feature a default setting, which requires RBS 3.2. Ruby 3.4 comes with a compatible RBS version bundled. This is beneficial for all features related to code insight.Better remote development experienceWe are continuing to enhance RubyMine remote development as an alternative to using just remote Ruby interpreters. In 2025.2, you will enjoy an even better overall performance and several improvements to split mode.AI Assistant improvementsIn the new release, you can expect AI Assistant to generate more code suggestions across your projects. The quality of multi-line suggestions will also improve now that the formatting of outputs has been fixed.Whats more, in line with our efforts to expand AI Assistants functionality, we have improved code completion for ERB in RubyMine 2025.2.Join the Early Access ProgramYou can download the latest EAP build from our website or via the Toolbox App. The full list of tickets addressed by this EAP build is available in the release notes.Stay connected through our official RubyMine X channel. We encourage you to share your thoughts in the comments below and to create and vote for new feature requests in our issue tracker.Happy developing!The RubyMine team0 Σχόλια 0 Μοιράστηκε 26 Views


και άλλες ιστορίες